重删与层次化存储
层重删与层次化存储
文献笔记
参考文献
- Nitro: A Capacity-Optimized SSD Cache for Primary Storage(2014)
- CacheDedup: in-line deduplication for flash caching(2016)
- Austere Flash Caching with Deduplication and Compression(2020)
- Libra: A Space-Efficient, High-Performance Inline Deduplication for Emerging Hybrid Storage System(2023 ISPA CCF-C)
- EDC: An Elastic Data Cache to Optimizing the I/O Performance in Deduplicated SSDs(2022 TCAD)
Nitro 2014
1 简介
- Notro:
- 一种SSD缓存,利用了重删、压缩和较大的替换单元来加速IO
- 难点:压缩、重删与FTL读粒度、擦除粒度的不匹配,重删会影响SSD中块的擦除(部分页面被其他页面引用时)
- 设计:
- 在重删收益高的负载上进行重删
- 将变长的压缩输出打包成更大的单元WEU,与SSD内部块大小对齐
- 使用WEU级别的缓存替换策略来减少擦除
- 在FTL上层实现,在重删、压缩、RAM、性能、SSD使用寿命之间trade-off
2 架构
- 上部为CacheManager,维护一个file index从文件的句柄到ssd位置的映射;维护一个用于重删的指纹索引;dirty list记录会写模式下的脏数据
- 下部为SSD缓存
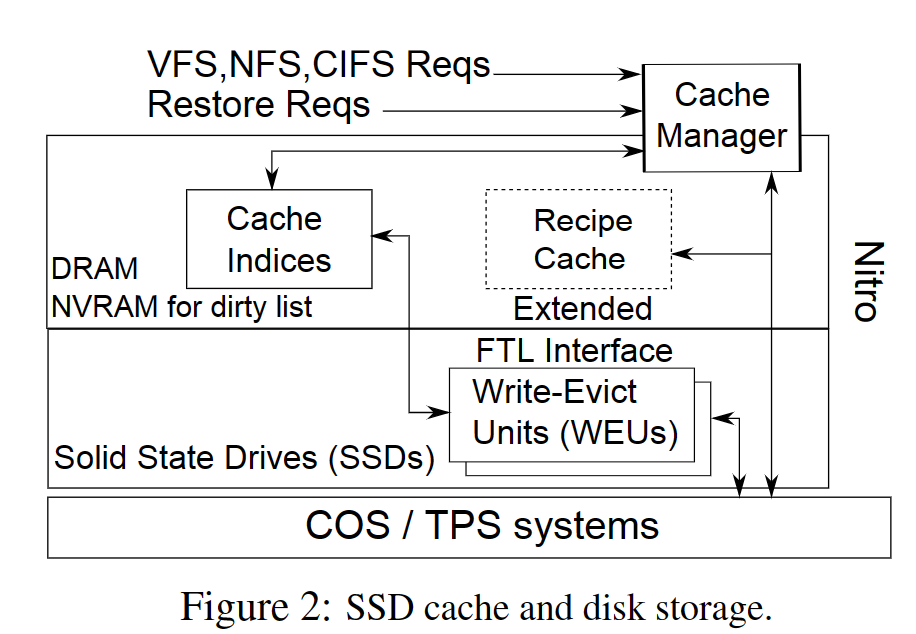
2.1 组成
- Extent: 一个extent是数据缓存的基本单元,cache index引用的在ssd中压缩并保存的extent
- 写入驱逐单元 WEU: SSD中的替换单元,file extent会被压缩打包到WEU中,满了后写入SSD;为了最大化并行性并减少内部碎片,WEU的大小是一个或多个block
- 文件索引: 文件句柄、偏移到extent在WEU中位置的映射
- 指纹索引:extent指纹到extent在SSD中位置的映射
- recipe cache: 将文件表示为引用extent的指纹序列,这样在重删中可以检索到已存在的extent
- 脏表: CacheManager支持写穿和写回模式,脏表记录写回模式下的脏数据即未刷入磁盘的extent
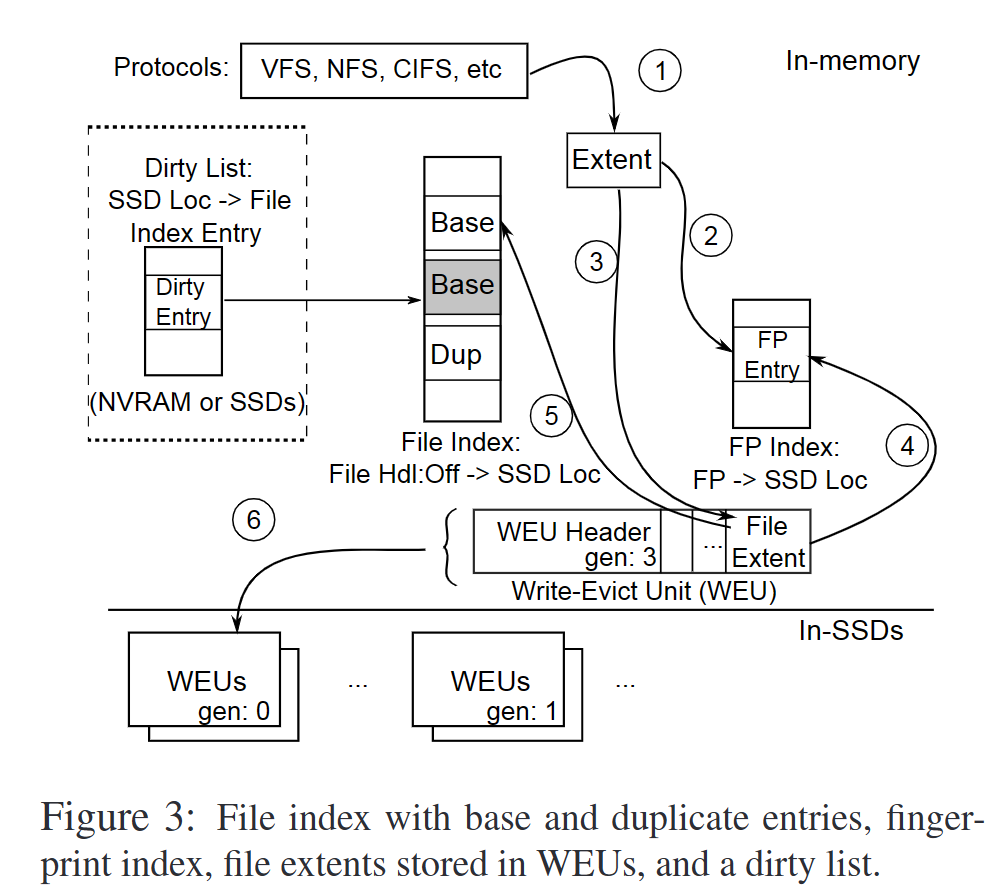
2.2 功能
- 文件读
- 命中:从WEU中去读压缩后的extent并解压,并更新对应WEU在LRU中的状态
- 对于基本条目,通过对比在SSD中读出extent的header判断是否是最新的
- 对于冗余条目,通过对比WEU中的生成编号判断是否是最新的
- CacheManager维护一个辅助结构记录WEU是在内存中还是SSD中
- 缺失:将file recipe预取到recipe cache中
- 后续读请求可以通过recipe cache获得fp,并根据指纹缓存检索到extent
- 如果recipe cache命中(冗余),则返回数据并更新状态,未命中则从HDD中读取,并执行缓存插入
- 命中:从WEU中去读压缩后的extent并解压,并更新对应WEU在LRU中的状态
- 文件写
- 写extent会被缓存到NVRAM中,并由CacheManager执行异步SSD缓存
- cache插入
- 1 计算来自读缺失or写入的extent的FP
- 2 查指纹索引,命中则更新LRU状态并到5,否则到3
- 3 将extent压缩,写入WEU中并更新WEU的头
- 4 更新指纹索引,把FP映射到WEU中的位置
- 5 更新文件索引,把文件句柄映射到WEU中的位置
- 6 当WEU满,写入生成编号,写入SSD中,在写回模式中脏extent和干净的extent分别写入不同的WEU中,简化驱逐
- 写包含重复内容时会创建重复的条目指向旧的extent在SSD WEU中的位置,减少更新header带来的擦除
- cache替换
- 由FTL来决定替换
- 文件索引清理
- 使用异步的方式,通过后台清理线程,检查所有的冗余条目看生成号与WEU的生成号是否一致,不一致则删除
- 快照恢复与访问
- 系统重启
- CacheManager通过从SSD中读取日志(跟踪extent的脏、无效状态)、读取WEU头来快速创建索引
3 实现
- FTL修改
- 支持对齐的块中跨多个平面的连续物理页分配
- 改进SSD GC算法,实现WEU替换
- 添加SATA TRIM指令,让一段SSD逻辑地址失效
- 模拟器是混合映射模式,块被分为数据块和日志块,通过合并操作,将页面映射的日志块合并为块映射的数据块。日志块进一步分为顺序区域和随机区域,以减少昂贵的合并操作。
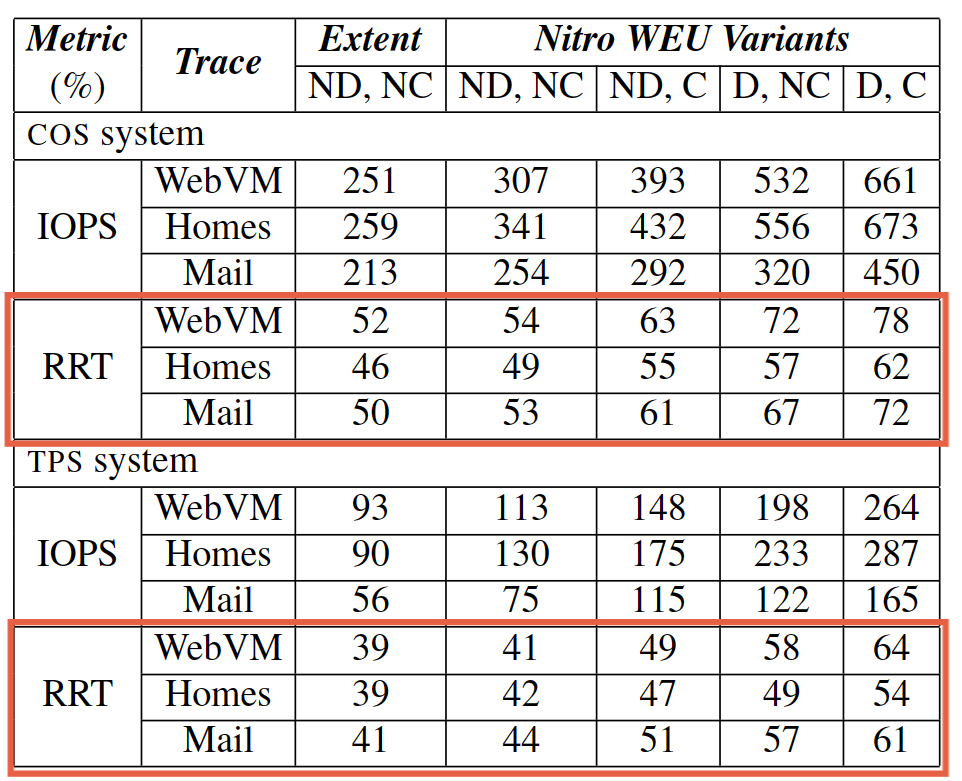
4 验证
- 请求响应时间增加,IOPS增加
- 随机读性能提高,快照恢复性能提高,写ssd次数减少
CacheDedup 2016
1 简介
- 将Flash用于DRAM和HDD之间缓存数据的关键问题
- 1 对Flash内存的容量要求高,传统商用Flash设备容量有限
- 2 Flash内存存在耐久性问题,容易磨损
- CacheDedup的贡献
- 1 使用重删减少工作负载对cache容量的占用
- 2 通过重删提高命中率,减少cache换入造成的磨损问题
- 3 通过新颖的架构对cache和dedup的高效、无缝集成与管理,即将数据源地址和指纹集成管理,解决的关键问题:
- 允许CacheDedup限制元数据空间使用,灵活部署
- 当数据在DataCache中被换出是,可以在MetadataCache中保存历史源地址和指纹,当再次引用这些数据时可以命中
- 4 缓存替换算法Dedup-aware LRU,Dedup-aware ARC
2 背景
- 直接在cache上堆叠去重层是不好的(没有读懂)
- cache无法利用重删后节省的空间
- 去重层需要管理主存指纹,可能做出不利于缓存的指纹管理决策
- Nitro是server端的结合了重删-压缩的flash cache,CacheDedup的特点在于架构以及其dedup-aware cache管理机制
- 重删可以in-line、in IO path、offline,CacheDedup使用in-line重删
- 采用固定大小的cache block级别的重删能取得良好的效果
- LRU不是抗扫描的,只访问一次的项目会占用cache空间;ARC抗扫描的自适应替换算法;现有的缓存替换算法不考虑磨损
3 架构
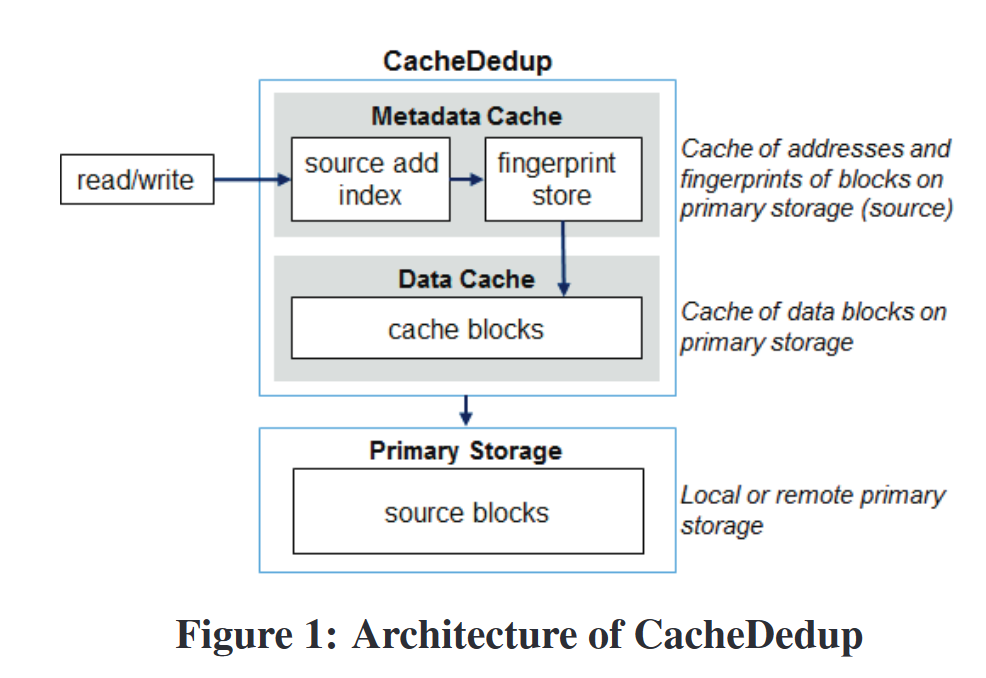
3.1 CacheDedup架构
- 问题特性
- 去重的引入使得源地址-cache地址的映射关系变成多对一,Cache的容量问题缓解
- 追踪被驱逐块的指纹,可以在再次引用时命中
- MetadataCache:存储源地址和指纹
- source address index: 主存中的源地址->MetadataCache中的指纹,多个源地址可能会对应到同一个指纹
- fingerprint store: 指纹->DataCache中块地址,其中包含了历史指纹即DataCache中不存在的块;每个指纹有引用计数即被几个源地址引用,当某个指纹的计数为零会被MetadaCache删除[不存在指纹未被地址引用,但存在指纹引用数据块围在DataCache中]
- DataCache:存储数据块
3.2 CacheDedup操作
- 读操作
- 只有在MetadataCache中找到源块地址,并且其指纹指向DataCache中存在的块时才算命中;指纹指向的历史数据块为未命中
- 未命中时,从主存获取数据,当其不是冗余块时插入DataCache中,如果其指纹已存在MetadataCache中,则将其指向新数据块
- 写操作
- 写无效:将MetadataCache和DataCache中对应条目记为无效
- 写穿:写入缓存(不存在则插入缓存,如果写入的数据与DataCache中匹配则将其指纹的引用计数+1,如果写入前的数据在DataCache中由于修改要将其计数减-1)和主存
- 写回:只写入缓存中
3.3 容错
3.4 部署
- 可以部署在客户端和服务端
- 客户端:通过缓解网络IO延迟提升应用性能
- 服务端:利用多客户端的IO来提高重删效率,需要考虑一致性
- 还能融入FTL层中;可以通过将块地址->文件句柄、文件偏移来实现文件系统级别的读写缓存
4 算法
- 采用no-wastage策略,不允许鼓励地址和鼓励数据块同时存在
- DLRU
- 不会影响空间浪费,形式化证明见文
- MetadataCache和DataCache独立进行替换

- DARC
- DataCache(大小为$C$)
- 使用4个LRU队列$T_1,T_2,B_1,B_2$存储元数据(总大小为$2C$),将频繁访问的放入$T_2$,将扫描数据放入$T_1$,$T_1$与$T_2$的比例由自适应参数$p$控制;
- 使用$B_1,B_2$保存对应的被驱逐的元数据,如果再次引用则放入$T_1$或$T_2$中,并自适应调整$p$
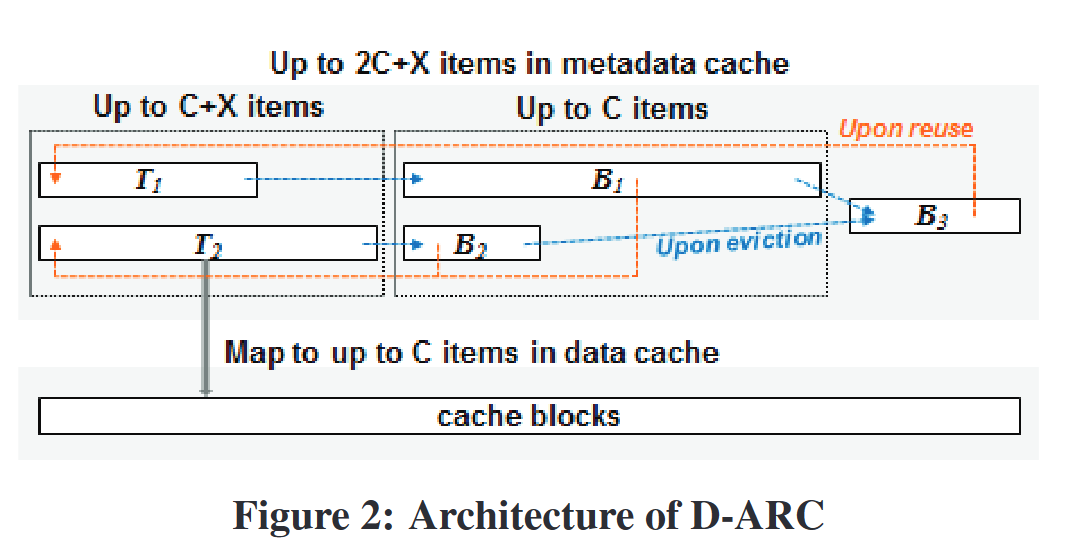
- $B_1、B_2$可以最多存放$C+X$个地址,$X$由系统自动调整
- $B_3$存储从$B_1、B_2、T_1、T_2$中驱逐的条目,利用$B_1 \space B_2$的多余空间,如果命中则插入$T_1$中二不改变参数$p$
- 详细伪代码见论文
- DataCache(大小为$C$)
AustereCache 2020
1 简介与背景
- 在传统的flash cache上加入压缩和去重会增加管理开销,额外的内存放大可到16倍
- AustereCache:一个内存高效的flash cache,结合了重删和压缩,并降低了索引的内存开销
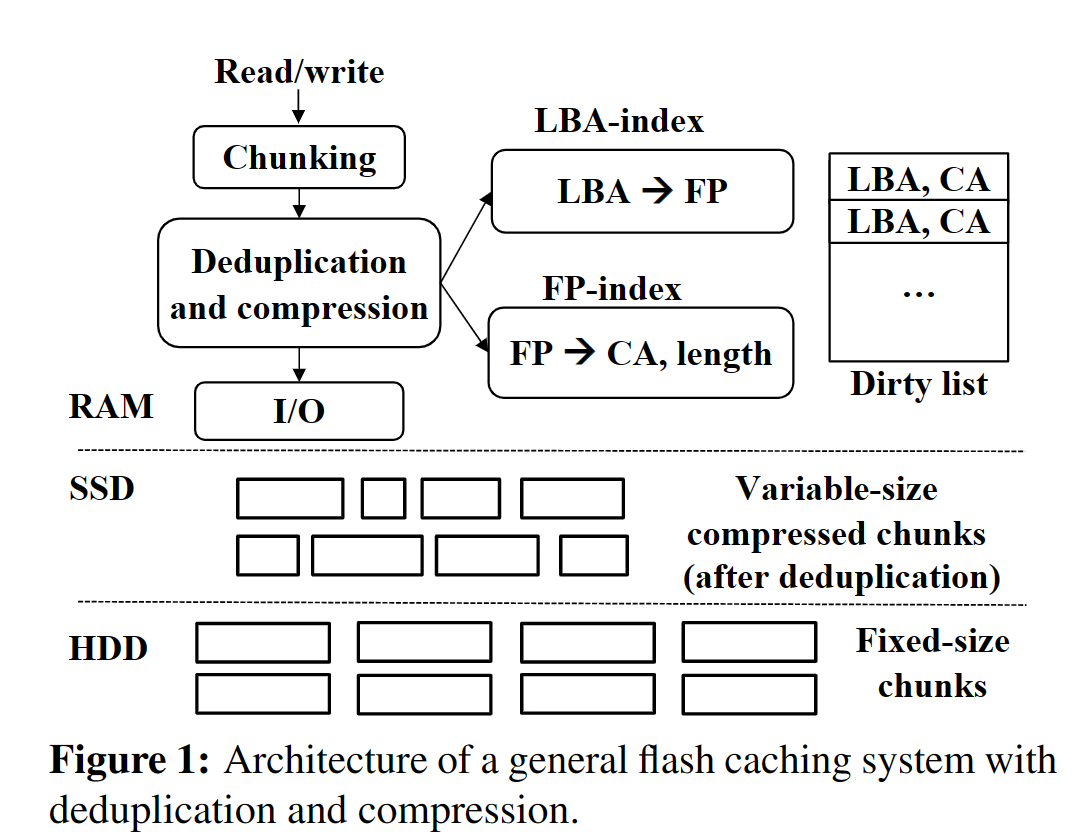
- 内存放大问题,使用上图的传统架构时,4TB的负载需要共4GB的内存来存储元数据和索引,而不使用压缩和去重时只需要256MB,放大率高达16倍
- Nitro:容易受到孤块影响,这些块没有被任何地址、指纹引用但由于LRU策略导致无法释放
- CacheDedup:结合了压缩和去重的CD-ARC也会受到孤块的影响,虽然CDAC提升了性能但是内存放大问题严重
2 设计
- 桶化
- 索引结构
- 将LBAindex和FPindex分为大小相同的桶bucket,桶由大小相同的槽slot组成;Flash Cache被划分为metadata region和data region
- 对LBA和FP计算哈希值,LBA-hash和FP-hash,将其前缀(16位,0.2%的碰撞概率)作为在LBA-index和FP-index中的key
- 而在Flash SSD的元数据区域中保存其完整的LBA和FP,使得出现哈希碰撞时可能出现miss而不会丢失数据
- 写路径
- 写入需要更新LBA-index和FP-index,LBA-hash的后缀用于指定放置的桶,扫描桶中所有的槽看是否存在相同的LBA-hash前缀,不存在则写入空槽或驱逐一个槽再写入
- 去重路径
- 对于(LBA,FP)指定的写入块,首先在FP-index中根据FP-hash的后缀定位桶,然后扫描所有槽是否由相同的FP-hash前缀
- 存在则看Flash SSD中metadata,其FP是否与槽中FP匹配,匹配则认为是重复数据,并将其LBA加入list中,如果不匹配则出现了哈希碰撞并按
- 读路径
- 访问LBA时,先查LBA-index在对应桶中找到FP-hash,然后查FP-index找到相同FP-hash prefix的槽,然后再Flash SSD中找到对应的槽并LBA列表中是否有对应的列表,找到则缓存命中,否则从HDD中读取
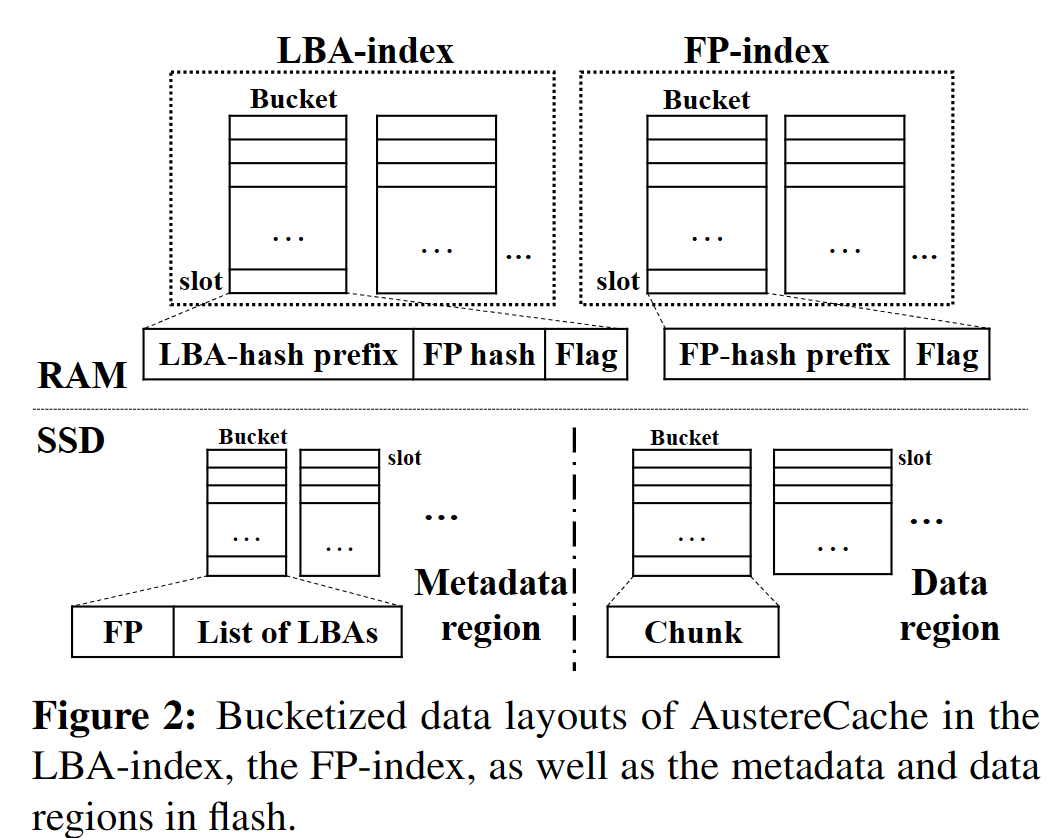
- 索引结构
- 定长压缩数据管理
- 把压缩好的块分成定长子块,尾块不足部分填充,FP-index和Flash SSD中的Metadata分配与子块个数相同的连续slot,Flash SSD中只写入一次其余空着
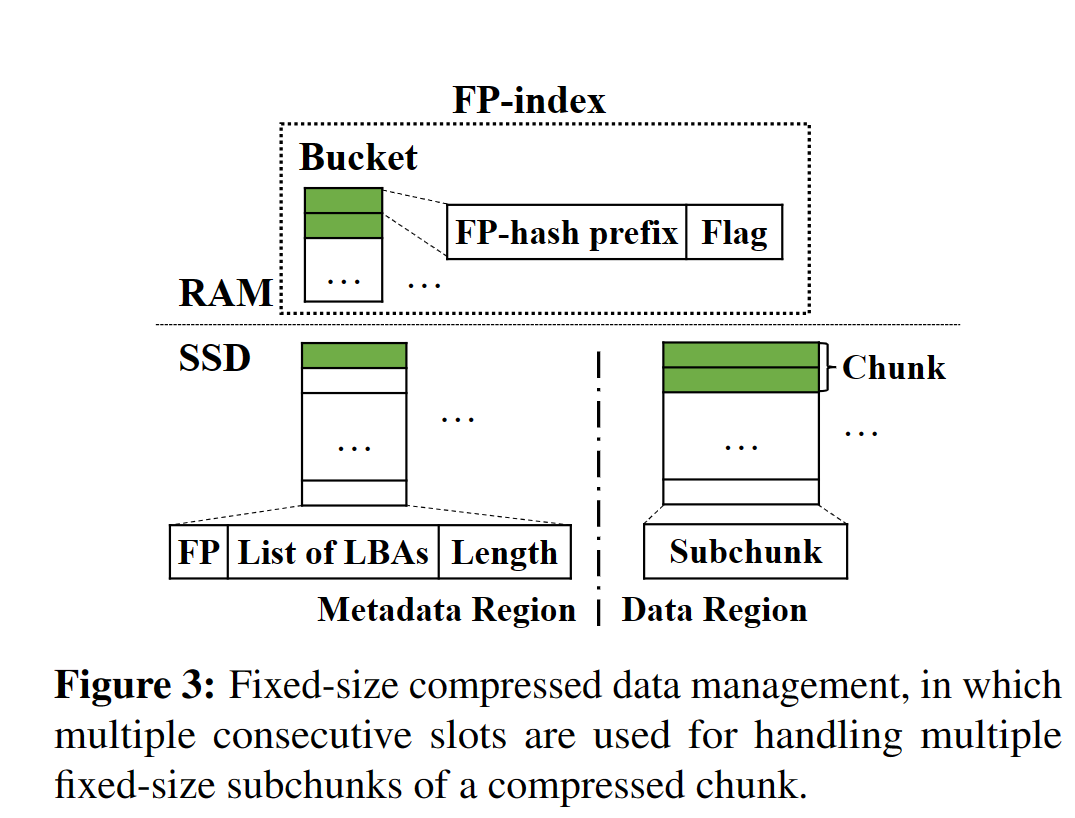
- 基于桶的缓存替换
- LBA-index使用基于桶的LRU策略
- FP-index基于引用计数的策略
想法
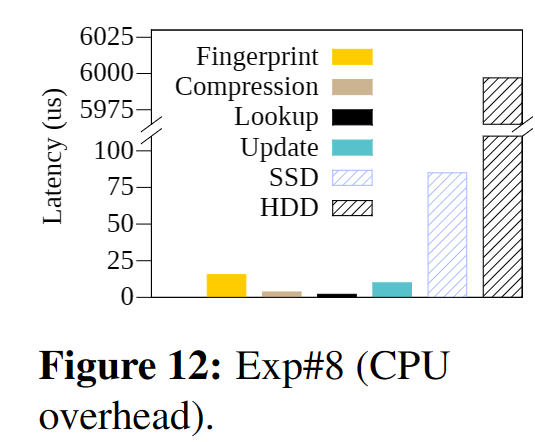
- 只有对重删、压缩和IO的CPU Overhead的分析,没有延迟上的横向分析
Libra 2023
1 简介
- 新兴存储系统上的出现有以下几点新变化
- 内存和Cache之间的速度差异变小,内联的去重对运行时开销更加敏感
- 由于新器件贵,Cache中存储元数据的空间开销不能忽视
- 新器件具备高耐久性,能容忍更多的写入
- Libra的三个关键部分
- 内存-cache联合索引
- 选择性去重,绕过频繁更新数据
- 低开销、低误判率的历史元数据记录
2 背景与动机
- 在使用新器件作为Cache时,CacheDedeup比AustereCache有更高的吞吐量,因为后者会在memory和cache之间做频繁的映射交换;AustereCache的元数据开销还需要占用cache空间,而CacheDedup的元数据均位于内存中。需要考虑重删后的性能和空间问题

- 冗余数据成高度偏斜的zipf分布,使用冗余感知的内存替换策略,只需小容量的FP-index就可以取得高去重率
- LBA-index和FP-index之间利用率不对等,因此大小相等的index设计不适合
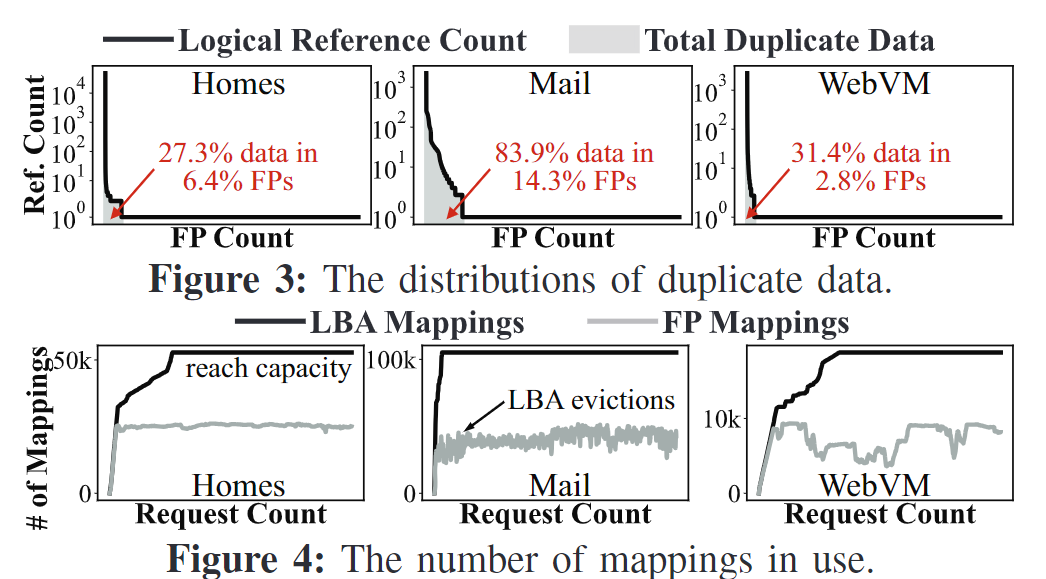
- 对于频繁更新的数据做重删没有意义,实验显示更新后的数据被再次更新的概率越大
3 设计
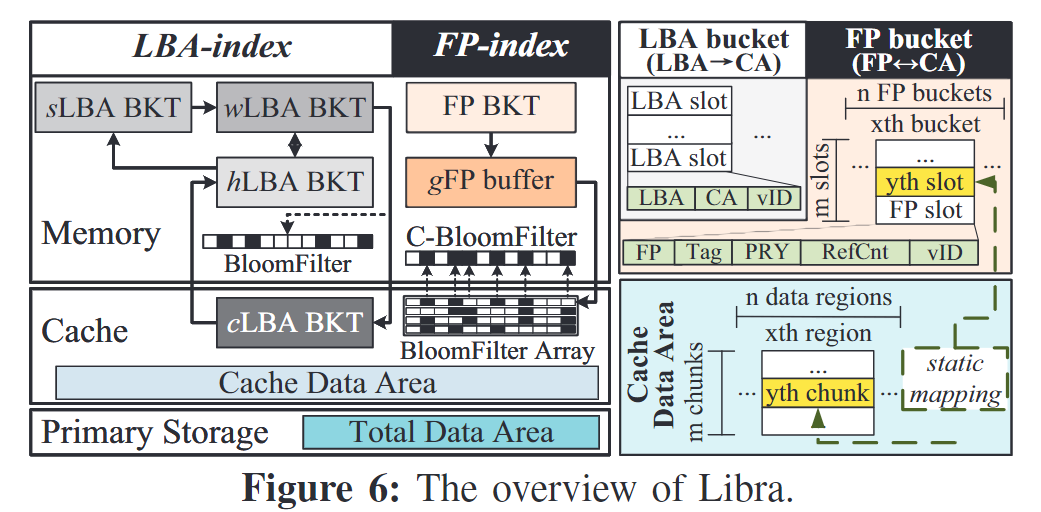
3.1 Overview
- LBA-index
- sLBA-index BKT:即将更新的(跳过的)LBA bucket的映射
- h/w/cLBA-index BKT:热温冷的LBA bucket的映射,冷的放到cache中,热、温的放到内存中
- FP-index
- 内存:FP bucket(带优先级的最近使用FP)、ghost-FP bucket, counting-bloomFilter
- Cache:BloomFilter Array(与gFP BKT、c-bloomfilter一起记录历史数据,用于估计被驱逐的FP重用概率)
3.2 内存-cache联合索引
- LBA-index:直接缓存LBA-CA,CA只有4-8个字节,而FP较长(SHA-1有20个字节长度),也减少了读取时lookup次数
- FP-index:FP->CA,FP-index和Cache Data Area分成数量相同的FP bucket和data region,将第x个桶中的第y个槽映射到第x个数据区域的第y个chunk中。
- 这样不需要存CA值,还能快速地从FP->CA也可以在LBA-index时通过CA->FP
- 但是这样对淘汰Cache中CA数据时修改LBA造成了影响,因此为LBA、FP桶中的slot维护一个vID,记录CA被写入的次数;当LBA slot vID和FP slot vID不一致时,说明较小的vID的数据较旧
3.3 LBA-index
- LBA-index条目由LBA、CA、vID组成
- 选择性重删:两种策略来识别并保存to-be-updated的LBA
- 将更新两次以上的认为马上要更新
- 将sLBA桶的大小设置小点,使得较小的更新率也能受益于去重
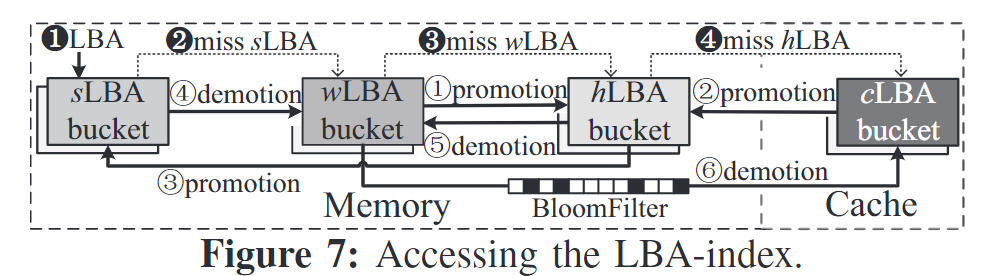
- 空间对其:sLBA占10%,cLBA=4xwLBA,使用布隆过滤器(FPR<10%)缩小内存和缓存间访问性能
3.4 FP-index
- FP-index条目由FP(FP指纹的前缀)、Tag(slot是否在使用)、PRY(不被驱逐的优先级)、RefCnt(被CA引用计数)、vID(写入计数)组成
- gFP buffer缓存较短周期内从FP bucket中驱逐的FP历史信息,c-bloomfilter缓存较长周期内驱逐的FP历史信息
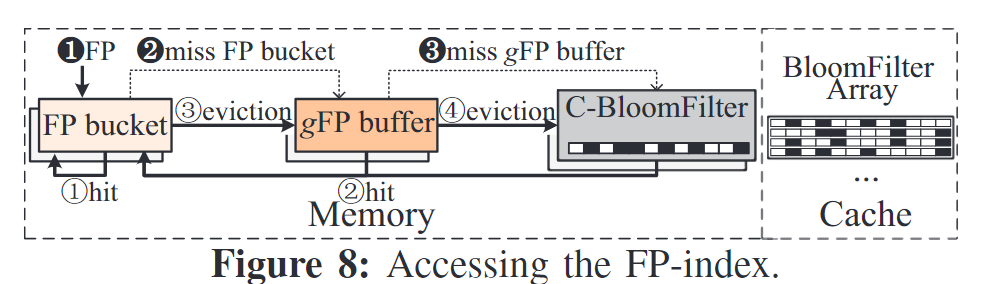
- gFP是通过对从FP bucket中驱逐的FP值做32位的xxHash得到,插入gFP buffer中
- 每个gFP buffer最多放128个gFP,当gFP buffer满时清除所有的其中gFP(不考虑驱逐gFP的局部性,由布隆过滤器来解决)
- C-BloomFilter由4个bloomfilter array来实现,每个的FPR在2.5左右,总体FPR在10%左右,任意一个误判则会出现误判($0.975^4 \approx 0.9035 $)
- FP Access Path
- 写入数据块时,首先根据内容计算FP,然后根据FP前缀定位到FP bucket,扫描是否有相同的FP存在
- 存在则命中,代表是冗余数据块,增加其PRY,LBA-index可以直接引用这个CA
- 不命中则计算xxHash,查历史记录gFP buffer,还未命中则查布隆过滤器;任一命中都将其提高到FP bucket中
- 采用轮询+时钟算法来做替换策略
- 写入数据块时,首先根据内容计算FP,然后根据FP前缀定位到FP bucket,扫描是否有相同的FP存在
重删与层次化存储
https://yee686.github.io/2024/03/08/重删和层次化存储/