EBS的发展历程(Fast 24 best paper)
What’s the Story in EBS Glory
1 EBS的发展历程
- 3代EBS发展历程:功能实现–>提高空间性能与空间效率–>降低网络流量放大
- EBS1: 采用存算分离架构,从虚拟磁盘VD到物理磁盘的原地更新,对虚拟磁盘的独占管理,通过无状态的blockserver独占管理VD(nVDs–1BS),但是直接虚拟化带来了严重的空间放大和性能瓶颈
- EBS2: 日志结构和虚拟磁盘分段,使用盘古分布式文件系统作为存储后端,重构blockserver使得将VD的所有写操作转换为追加操作;三副本;GC时进行后台压缩和纠删码编码;将VD分段到32GB的粒度,将空间效率从3提升到1.29;但是将流量放大了4.69倍(3副本+1后台GC读+0.69压缩/纠删码)
- EBS3: 通过在线压缩/EC减少流量放大,Fusion Write Engine和基于FPGA的压缩,FWR将不同段的写操作聚合以达到EC和压缩的大小需求,并使用FPGA来加速压缩,能在相近性能下实现1.59的流量放大和0.77的存储放大
2 高性能与健壮性简述
- Elesticity(弹性):提供不同级别的性能和容量;平均性能由硬件开销决定,尾延迟由软件开销决定。通过使用基于PMEM的一跳架构存储后端来最小化平均延迟,前台blockclient将业务从内核转到用户空间,进一步卸载到FPGA上,后台blockserver通过高并行实现吞吐量和IOPS提升
- Availability(可用性):随着VD分段和段迁移的引入,区域级别故障频繁,个体级故障可能会导致区域级和全球级故障。在控制平面中,通过联邦的BlockManager将VD分组,并由CentralManager协调
- Offloading:将关键的控制和数据路径卸载到硬件上进行加速,Client使用ASIC加速虚拟化,Server使用FPGA加速EC/压缩
3 架构演化
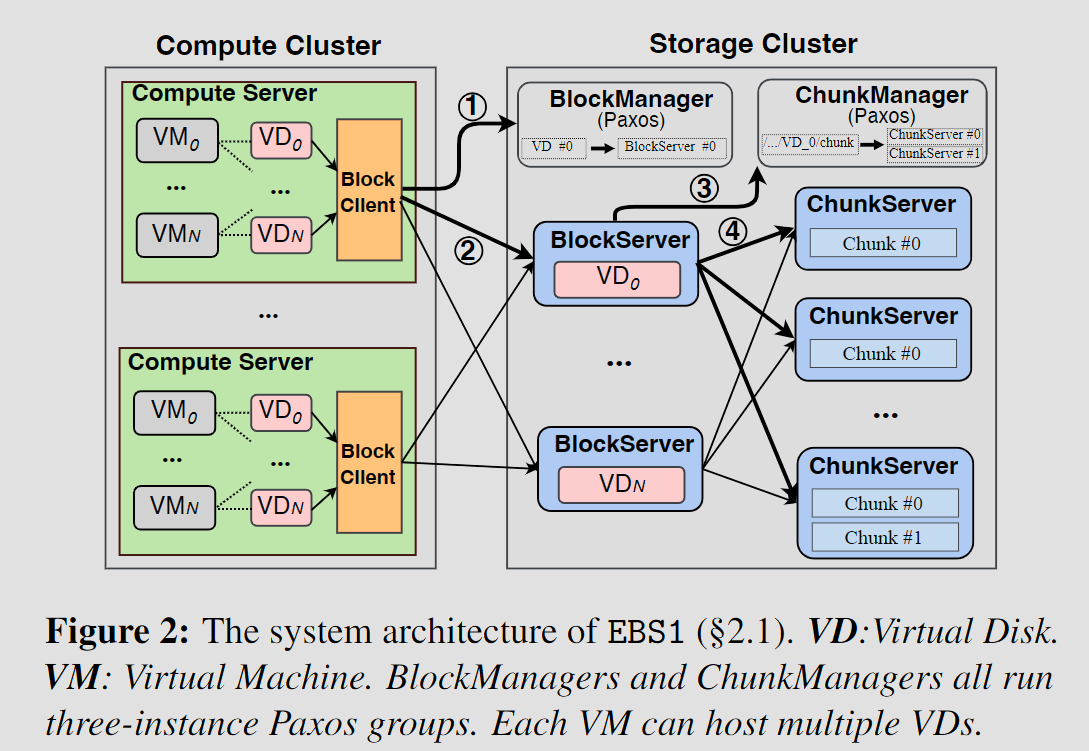
3.1 EBS1
- 计算端
- 每个sever上一个BlockClient,用户通过BC访问VD,BC将IO请求至存储端
- 存储端
- BlockManager(Paxos三节点):VD、BlockServer元数据维护,VD分配
- ChunkManager(Paxos三节点):chunk的元数据管理
- ChunkServer:将64M的chunk存储为ext4的DataFile,针对写执行原地更新
- Network
- Dataflow
- 不足
- Blockserver会受到突发负载下热点问题影响
- 压缩和EC写放大问题
- HDD和使用内核堆栈难以保证用户SLO
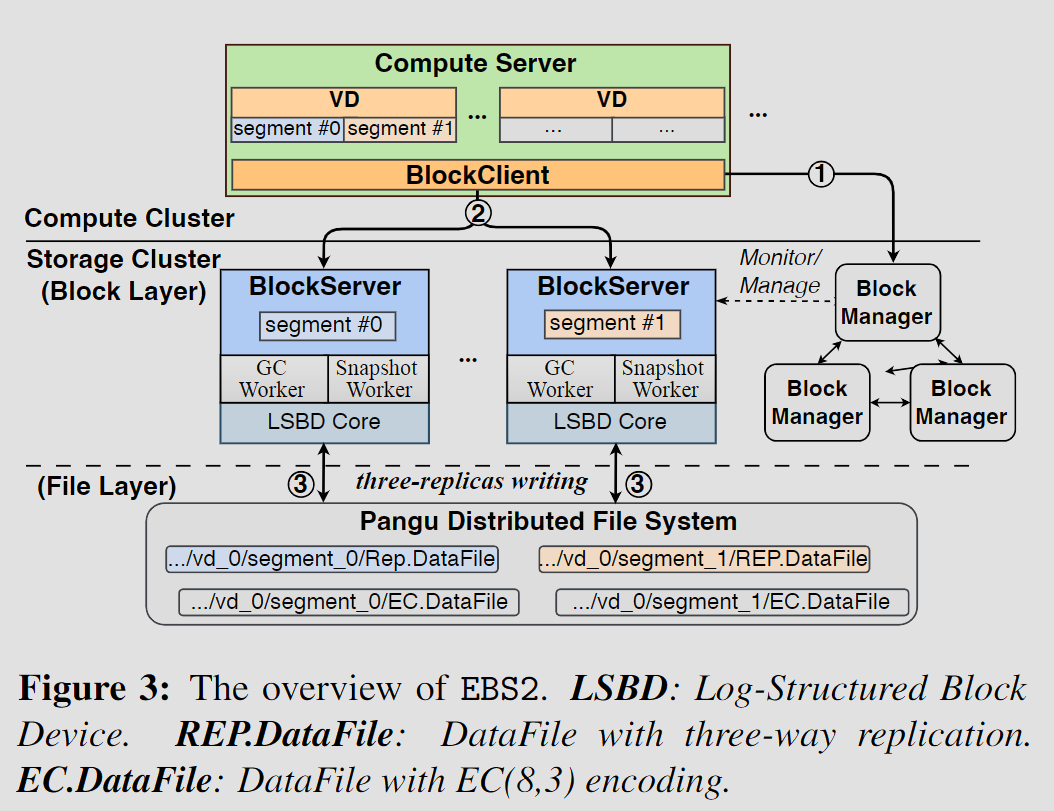
3.2 EBS2
- EBS不再直接持久化数据,使用盘古文件系统作为底层存储引擎,并使用日志结构重构BlockServer以支持盘古的仅追加语义,并有盘古负责分布式共识
- 引入VD分段使得单个VD可以有多个BlockServer处理单个VD,缓解突发负载下热点问题
- 数据流 Dataflow
- BlockClient收到VD请求时,先在BlockManager中检索地址
- BlockClient将IO转发给BlockServer
- BlockServer通过日志结构块设备(LSBD)core将IO操作转为盘古API,调用盘古客户端读写数据
- VD分段 Disk Segmentation
- 在块层,单块VD被分为多个128GB的段组,每个段组包含多个32GB的段,BlockServer以段为粒度
- 在文件层,一个段被多个512MB的DataFiles盘古文件持久化,以支持并行处理
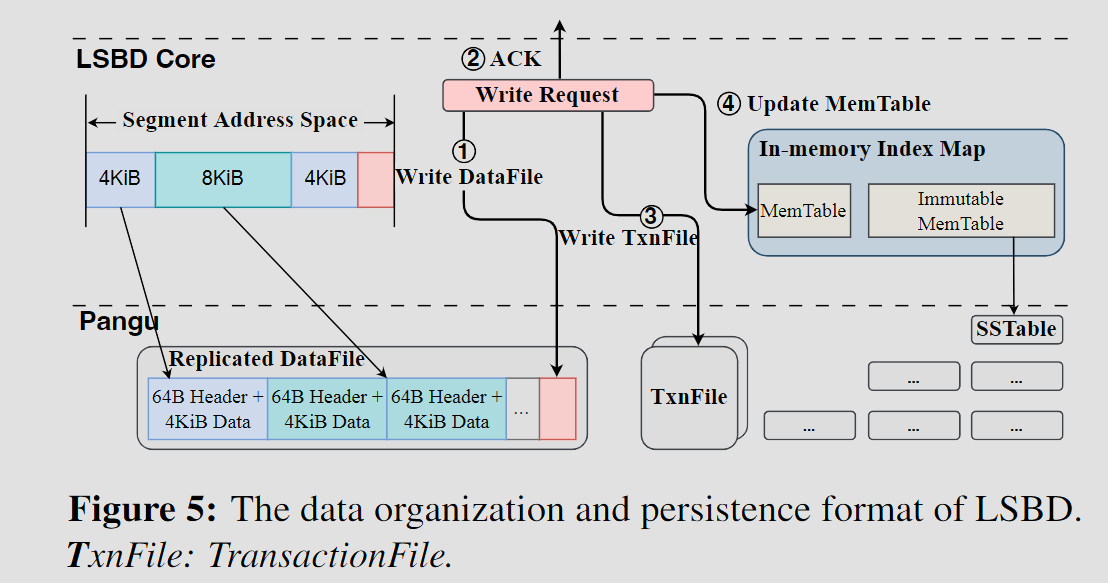
- 日志结构块设备 Log-structured Block Device
- 通过LSBD core来支持盘古的仅追加语义
- 使用LSM Tree来实现Index map记录VD LBA–>DataFile ID
- TxnFile用于在段迁移时加速Index map的重建
- 带EC和压缩的GC
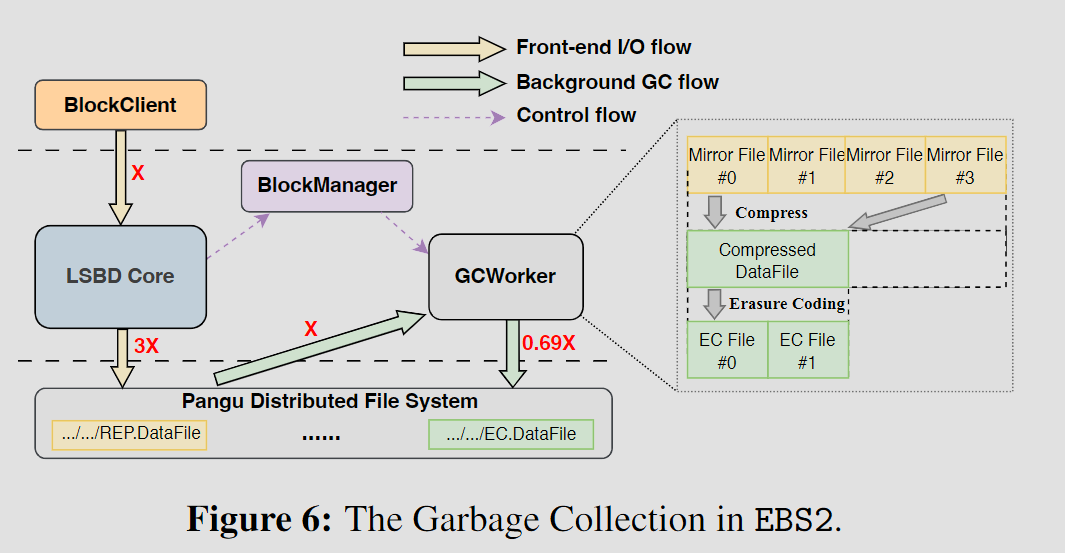
- GC粒度为Datafile,将REP.dataFile转为EC.dataFile
- 带高可用的BlockManager:将VD的元数据以盘古文件的形式存储到持久化的KV存储中
- 网络:在数据路径中,内核TCP–>用户空间TCP
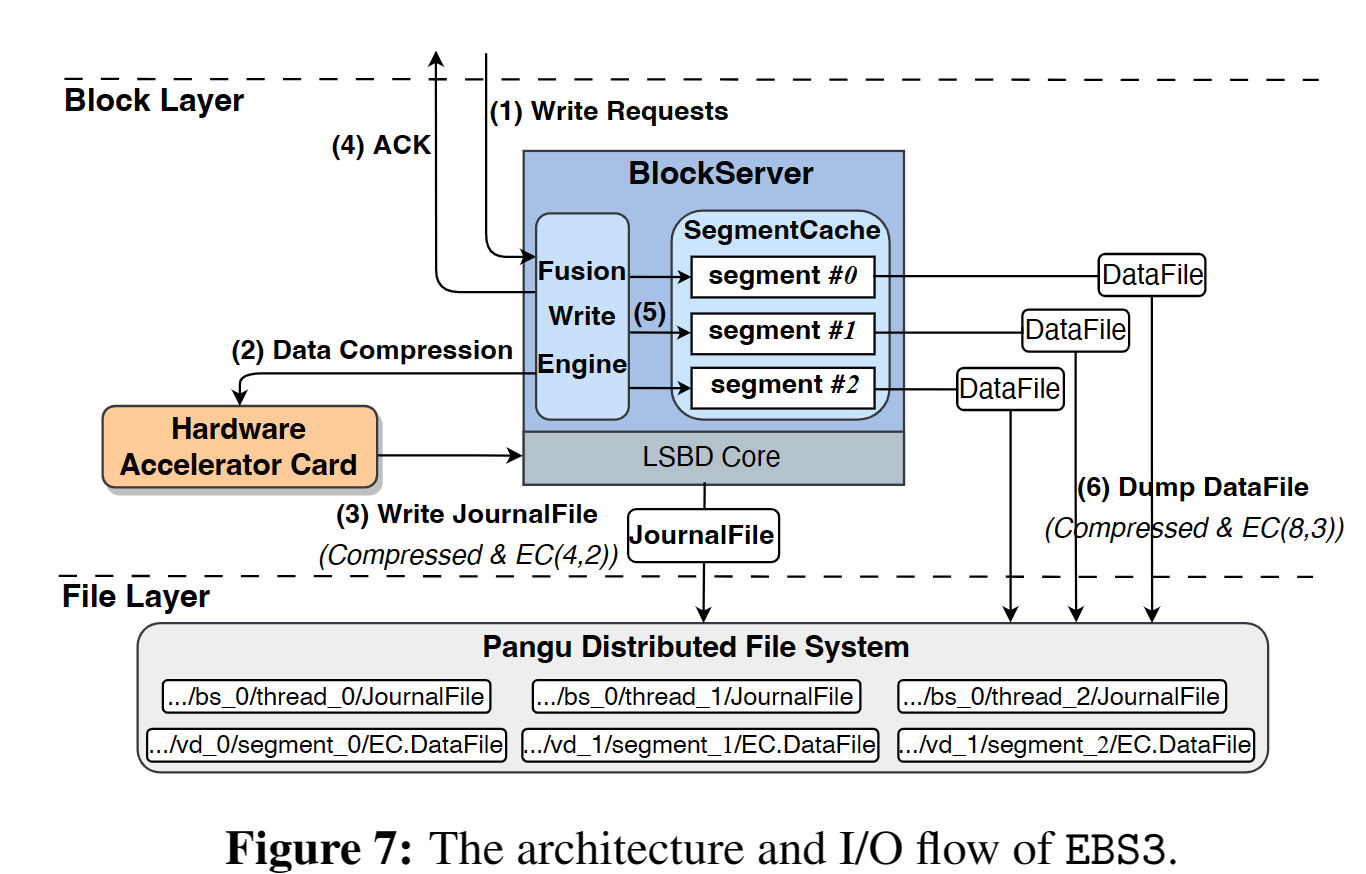
3.3 EBS3
- Overview
- Fusion Write Engine 融合写引擎
- 缓存小的写请求直至到达16kb,然后再给FPGA压缩
- 对于写入不密集的集群则不执行融合,以减少尾延迟
- 基于FPGA的压缩卸载
- FPGA内部实现调度器,将block切片,并行压缩
4 弹性
- 延迟
- 粗粒度,由体系结构、关键路径和硬件决定
- 软件栈导致尾延迟
- 吞吐量和IOPS
- 对EBS3 blockclient来说增加带宽IOPS会随着超线程的数量增加而增加
- 对blockserver来说,将请求划分可以增加并行性,提高吞吐量和IOPS,但是过小可能使得写入请求碎片化影响性能
- base+burst分配策略
- 基于优先级的拥塞控制:保证所有的baseIO以实现一直的延迟,而burstIO则视情况分配
- 服务器级动态资源分配:EBS2开始运行blockserver从后台任务中抢占资源以处理峰值负载
- 集群级热点环节:通过集群级负载均衡转移负载
- 总结:VD吞吐量和IOPS上限由客户端决定,后端容易扩展
- 容量
- 通过盘古文件的硬链接,下载单个快照来克隆存储集群中的多个磁盘,实现快速克隆
5 高可用
降低blast radius(global/reginal/individual)
5.1 控制面:联邦BlockManager
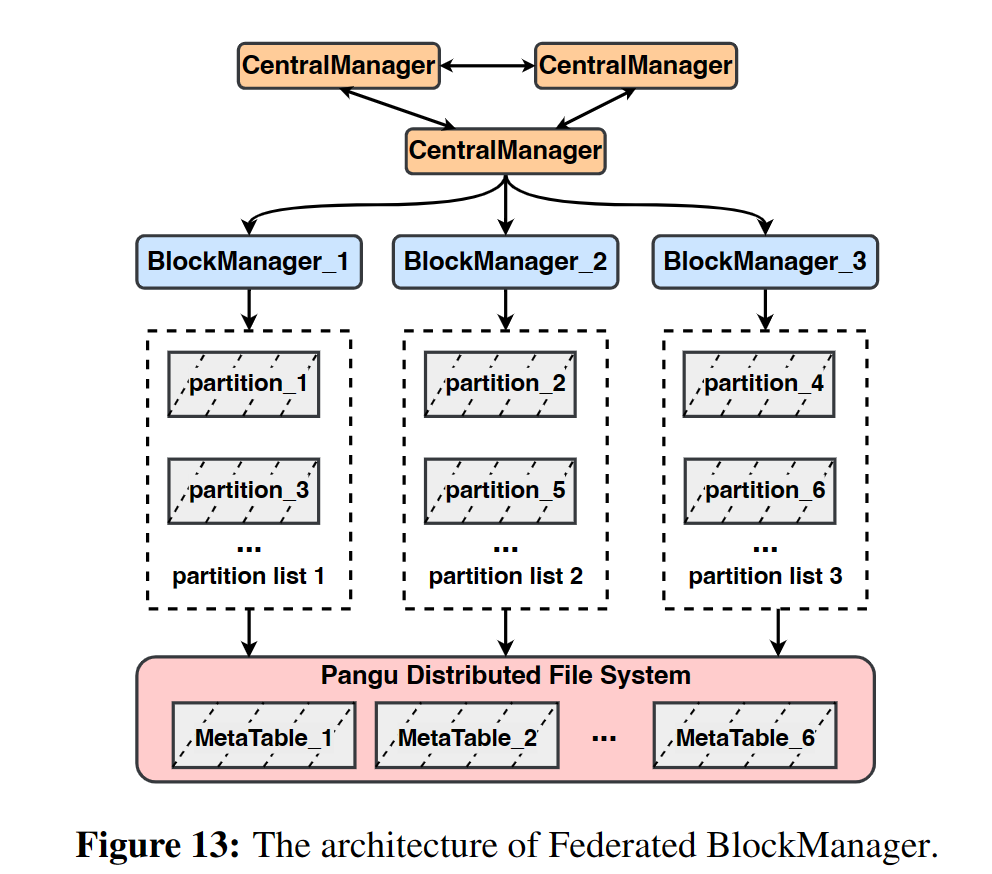
- 最初控制面(即blockmanager)采用三个节点组成,利用盘古的分布式锁选举leader,leader节点为集群提供所有的控制面服务,并将VD状态持久化到盘古的单个数据表中。
- 问题:单个节点为集群VD提供服务,随着VD规模增加扩展性会受到限制;由于只有leader节点有元数据表,数据表的部分损坏都会导致服务不可用
- 解决:联邦的blockManager
- 每个集群有多个blockManager,通过centralMananger协调管理,每个blockManager管理一部分(几百个)分区及其对应的元数据,哈希分区
- 每个blockManager只有一个节点,当故障时由centralManager重新分配对应的分区,并加载盘古中的元数据,为VD继续提供服务
- CentralManager只负责blockManager的驻车和分区调度
5.2 数据面:逻辑故障域
- 故障多源于单个VD或segment请求而不是BlockServer;多由于软件错误
- 逻辑故障域:将可疑的段放到一小组BlockServer中隔离
- 为每个段关联一个唯一的令牌桶token bucket,最大容量为3。每次迁移到新的BlockServer都会消耗一个令牌,并且令牌每30分钟重新填充一次。当令牌桶为空时,该段的任何后续迁移只能在三个预先指定的BlockServer中选择,这三个BlockServer被称为该段的逻辑故障域
- 令牌桶的设计限制了迁移的范围。当段成功加载到一个BlockServer中,并且能够立即为几分钟内的I/O请求提供服务时,解除故障域的限制
- 多个段形成一个故障域时(即其令牌桶都为空),为了避免多个故障域同时发生级联故障并导致集群停机,回将这些段合并为一个全局故障域。我们选择第一个形成故障域的段作为全局故障域的代表,其他段将共享同一个全局故障域。以确保最多有三个被隔离的BlockServer用于级联故障,而不会降低集群的容量。
6 what if
- 为啥不使用日志结构:
- 尽管日志结构设计可以解决数据聚合的问题,但它引入了额外的复杂性和开销。对于EBS3的前台EC/压缩操作,我们需要在持久化之前聚合足够数量的数据,以实现高效的数据减少。使用日志结构可能需要在不同虚拟磁盘之间进行段的合并和刷新,这会增加系统的复杂性,并且可能引入额外的延迟和开销
- 为啥Pangu和EBS要分离
- 底层持久化层与EBS解耦,并采用统一的日志结构接口,有助于开发和沟通的便利性。此外,独立的块层可以快速创建和迁移段,无论数据块的位置如何,都可以跨多个存储节点进行。分离的架构还将单点故障的影响范围局限在各自的层级上。
EBS的发展历程(Fast 24 best paper)
https://yee686.github.io/2024/04/02/EBS云存储/