ZNS SSD与键值存储
ZNS SSD与键值存储
[TOC]
调研笔记
参考文献
- RocksDB: Evolution of Development Priorities in a Key-value Store Serving Large-scale Applications(TOS 2021)
- Understanding NVMe Zoned Namespace (ZNS) Flash SSD Storage Devices (arXiv 2022)
- Decoupled SSD: Rethinking SSD Architecture through Network-based Flash Controllers(ISCA 2023)
- ZNS: Avoiding the Block Interface Tax for Flash-based SSDs(ATC 2021)
- ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Compaction(OSDI 2021)
- Accelerating RocksDB for Small-Zone ZNS SSDs by Parallel I/O(MiddleWare 2022)
- ZNSKV: Reducing Data Migration in LSMT-Based KV Stores on ZNS SSDs(ICCD 2022)
- eZNS: An Elastic Zoned Namespace for Commodity ZNS SSDs(OSDI 2023)
- Compaction-Aware Zone Allocation for LSM based Key-Value Store on ZNS SSDs(HotStorage 2022)
- SplitZNS: Towards an Efficient LSM-Tree on Zoned Namespace SSDs(TACO 2023)
- WALTZ: Leveraging Zone Append to Tighten the Tail Latency of LSM Tree on ZNS SSD(PVLDB 2023)
- Optimizing Data Migration for Garbage Collection in ZNS SSDs(DATE 2023)
- ZoneKV: A Space-Efficient Key-Value Store for ZNS SSDs(DAC 2023)
- Dynamic zone redistribution for key-value stores on zoned namespaces SSDs (JSA 2024)
- Lifetime-Leveling LSM-Tree Compaction for ZNS SSD(HotStorage 2022)
- LifetimeKV: Narrowing the Lifetime Gap of SSTs in LSMT-based KV Stores for ZNS SSDs(ICCD 2023)
- FlexZNS: Building High-Performance ZNS SSDs with Size-Flexible and Parity-Protected Zones(ICCD 2023)
- Para-ZNS: Improving Small-zone ZNS SSDs Parallelism through Dynamic Zone Mapping (DATE 2024)
- ZonesDB: Building Write-Optimized and Space-Adaptive Key-Value Store on Zoned Storage with Fragmented LSM Tree (TOS 2025)
RocksDB 综述 (TOS 2021)
1 RocksDB简介
- RocksDB是一种高性能持久性键值存储引擎,针对SSD、大规模应用程序进行了优化,仅负责管理节点上数据,具备高度的可配置性,被广泛用于数据库存储引擎(MySQL、MongoDB)、流处理(Flink、Kafka中存储分阶段数据)、日志和查询服务(利用压实机制和高写入吞吐量、低写入放大的特性)、索引服务(利用优秀读性能和批量加载功能)、SSD上缓存(Redis,较高的写入速率和准入控制机制)

2 背景
- SSD的使得性能瓶颈由IO转到网络延迟与吞吐量,可以在应用中使用键值存储利用本地SSD提升性能
- LSM-Tree是RocksDB的主要数据结构,主要操作:
- 写入:
- 待写数据先被加入内存中的写入缓存MemTable和盘上的预写日志Write Ahead Log(WAL)
- MemTable基于跳表实现,一旦MemTable和WAL满则不可改变,并分配新的MemTablehe和WAL
- MemTable刷入Sorted String Table(SSTable),SSTable是有序的并被分成了相同大小的block,每个块都有一个索引块用于二分搜索,丢弃已经刷入的MemTable和相关联的WAL
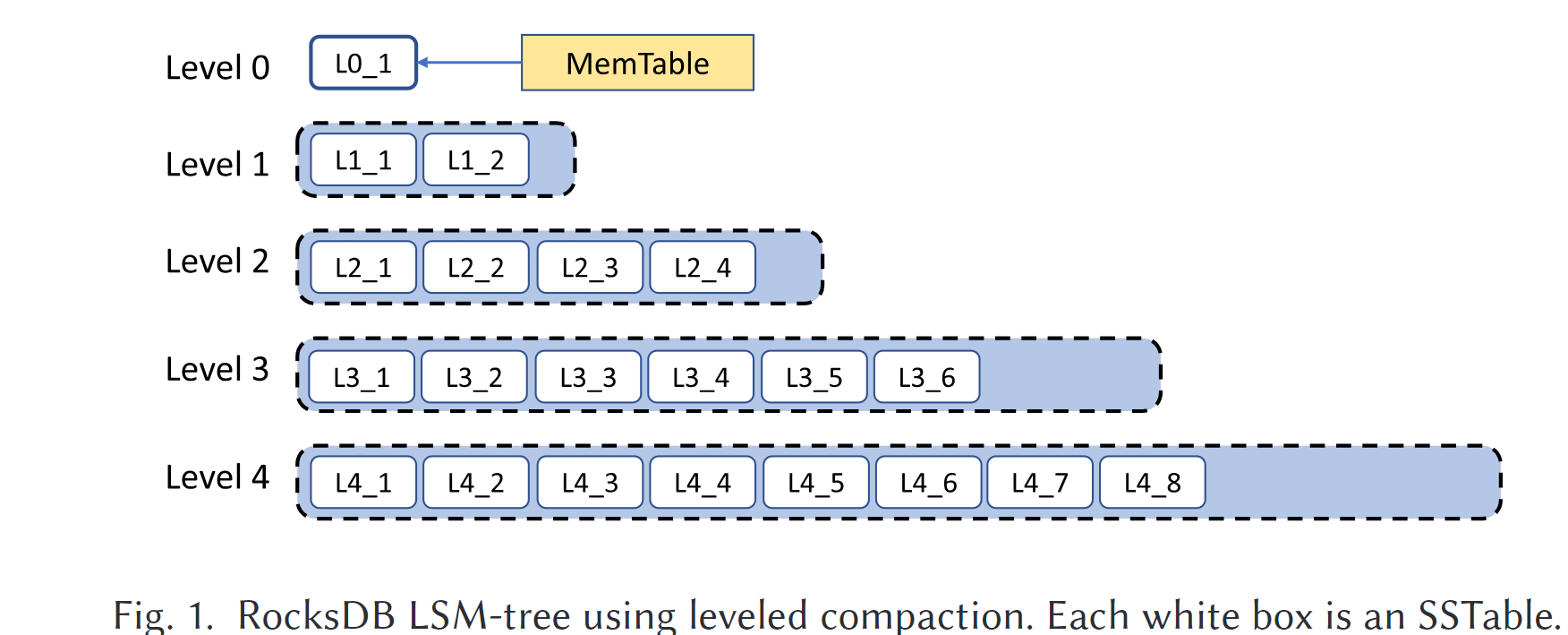
- 压实:
- level-0 SSTable由Memtable的刷入产生,其他更旧层的SSTable由压实操作产生
- 每一层的最大容纳的SSTable由可配置的参数决定,当第L层满时会将第L层的一些SSTable合并到第L+1层,合并过程中会产生新的SSTable
- 从level-1开始的较旧的SSTable的key是不重叠的
- Leveled compaction:LevelDB中所使用
- Tiered Compaction:一种lazy Compaction
- FIFO Compaction:轻量级Compaction,丢弃最旧的SSTable
- lazyier Compaction算法有利于减少写放大,提高写入吞吐率,而读性能降低;激进的Compaction则相反
- 压实层选择:选得分最高的level
- 非0层:SST总大小/目标大小(阈值)
- 0层:$max(SST文件数/设定的目标,SST大小超过指定值/设定目标)$
- 读取
- 首先搜索所有MemTable,然后搜索level-0 SSTable,最后搜索其他层的SSTable
- 较热的SSTable block会被缓存到内存的block cache中
- RocksDB
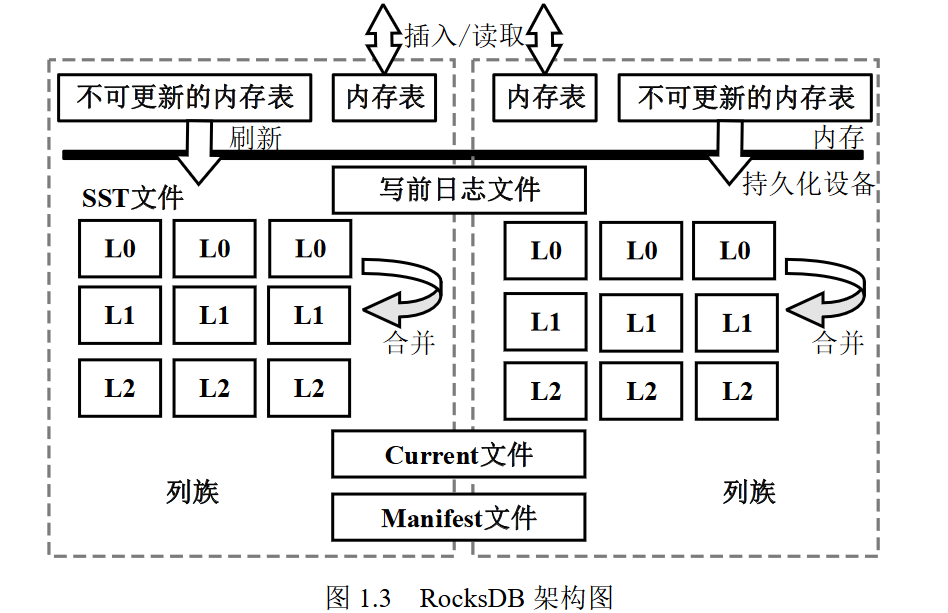
- 元数据
- Manifest文件保存数据块当前状态信息,每当SSTable文件被改动时会触发写Manifest,生成版本信息
- Current文件记录最新Manifest文件编号
- 列族:与LevelDB不同之处,为RocksDB提供逻辑分区,不同列族之间共享WAL,有独立的memtable
- 写入:
3 资源优化
写放大$\rightarrow$空间放大$\rightarrow$CPU利用率
KV接口
- 四种基本操作:Put、Get、Delete、Iterators(scan)
ZNS SSD综述 (2022)
- ZNS SSD的引入需要修改主机的存储软件栈,有以下四种集成方式
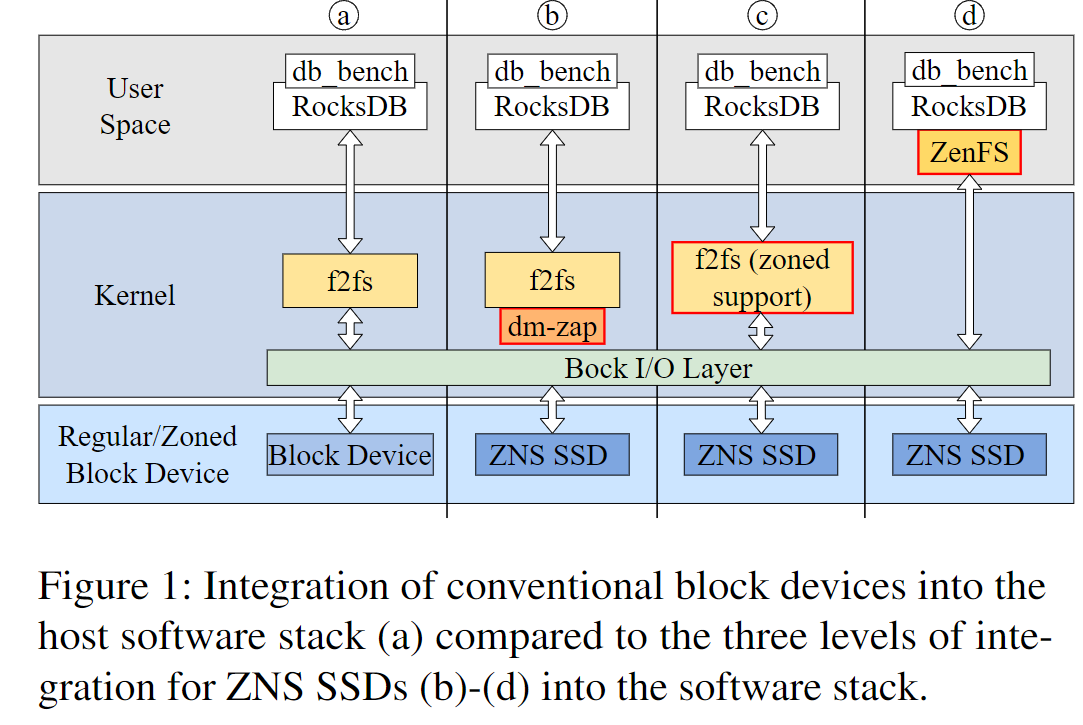
- 在块设备级别集成,例如在内核中使用dm-zap分区设备映射项目,侵入性小,对块设备的修改最小
- 文件系统级别集成,引入zone特性的支持(zone容量、活跃zone数目限制、追加限制等),如在f2fs上增加对zone的支持
- ZNS-aware应用程序级别集成,ZenFS+RocksDB
- OverProvisioning Space(op 空间):GC操作需要保持的额外空闲空间,例如FTL需要来移动有效数据的空间
- ZNS 存储:NVMe协议为zone设备(SMR ZNS)提供了统一的软件栈
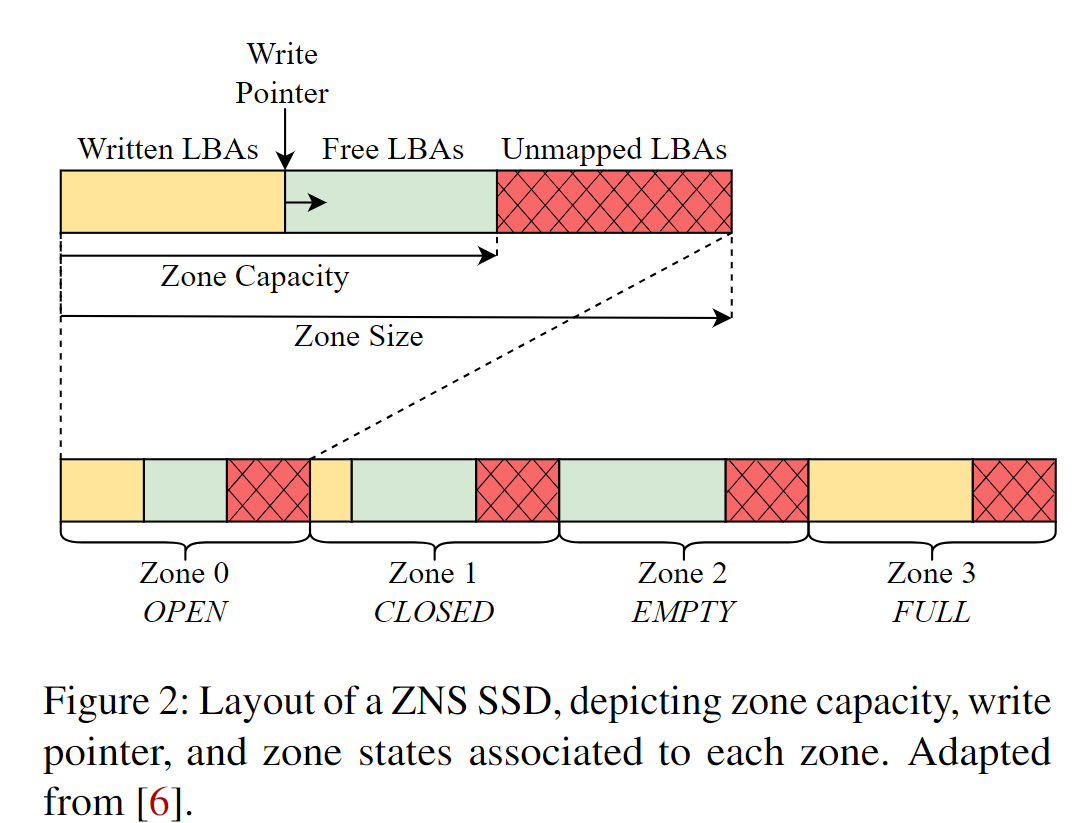
- zone capacity: zone的容量等于或小于zone size,其值与底层闪存介质对其的擦除粒度对齐
- active zone:最大的OPEN、CLOSED状态的zone数目
- zone append 命令:在一个zone中维护多个未完成IO,将数据写入write pointer位置,并将写操作的LBA返回主机;如果不使用该命令,需要保证IO的顺序性使得写入在正确的LBA上。
- ZNS的写入直接使用IO,绕开页面缓存以确保顺序写入
- ZNS IO调度
- 为了在多个待处理的IO下满足ZNS设备的顺序性写入,需要设置适当的调度器。调度器负责确保写入操作在设备上连续的LBA上提交
- 由于设备上的请求可能被重新排序,所以主机需要保证顺序,mq-deadline调度器强制只提交1个写入IO并保持后续IO直到提交IO的完成;如果设置为none则会绕过内核的调度器,并使用同步方式请求IO,由主机自己确保顺序性
- ZNS 应用集成
- f2fs: segment$\rightarrow$section(zone),segment与zone对齐
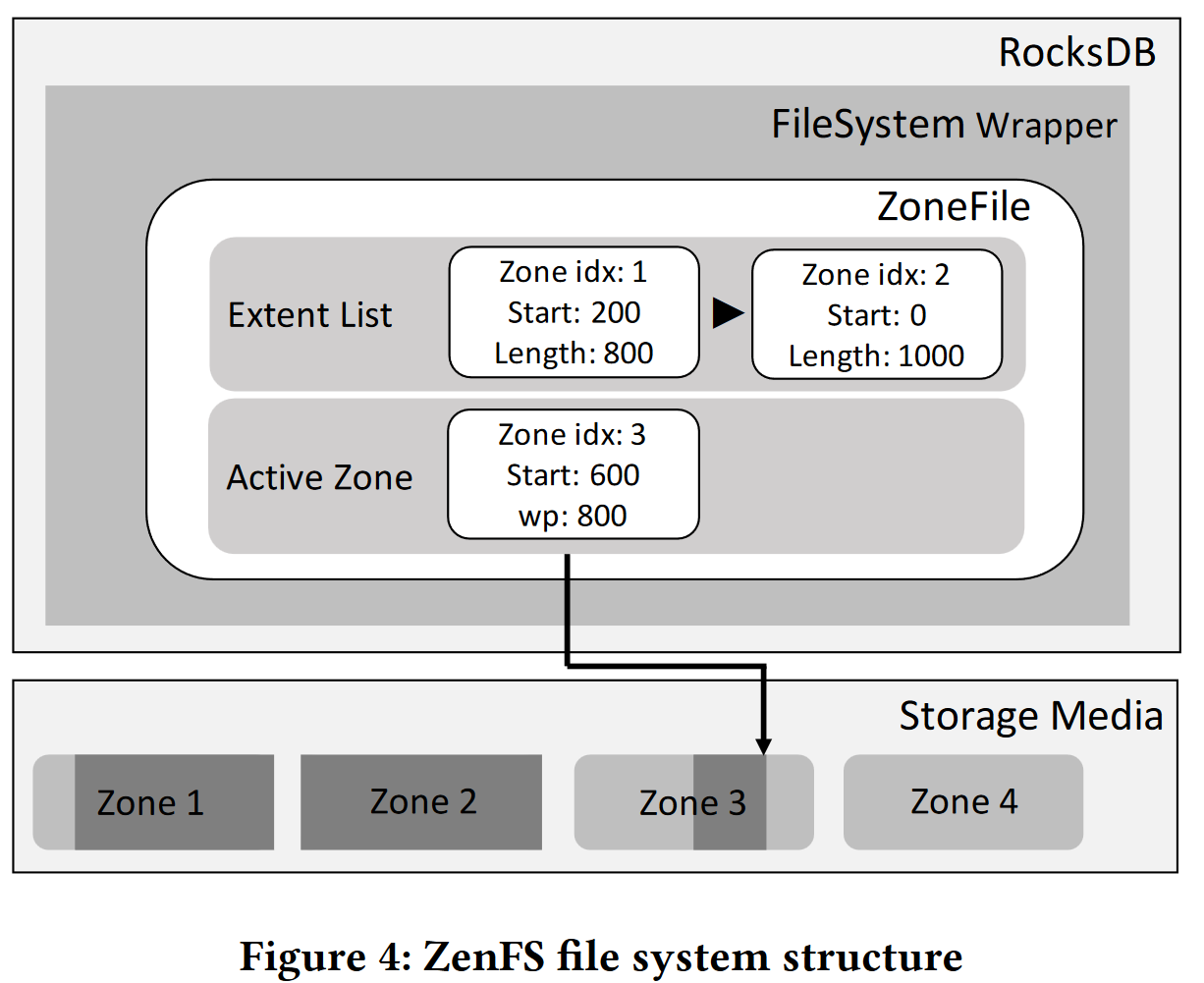
- ZenFS:
- SSTabel是不可变的,且按顺序写入,被当作整体单元擦除,是flash友好的
- zenfs将RocksDB数据文件映射为一组extent,extent是可以被顺序写的连续区域
Decoupled SSD (ISCA 2023)
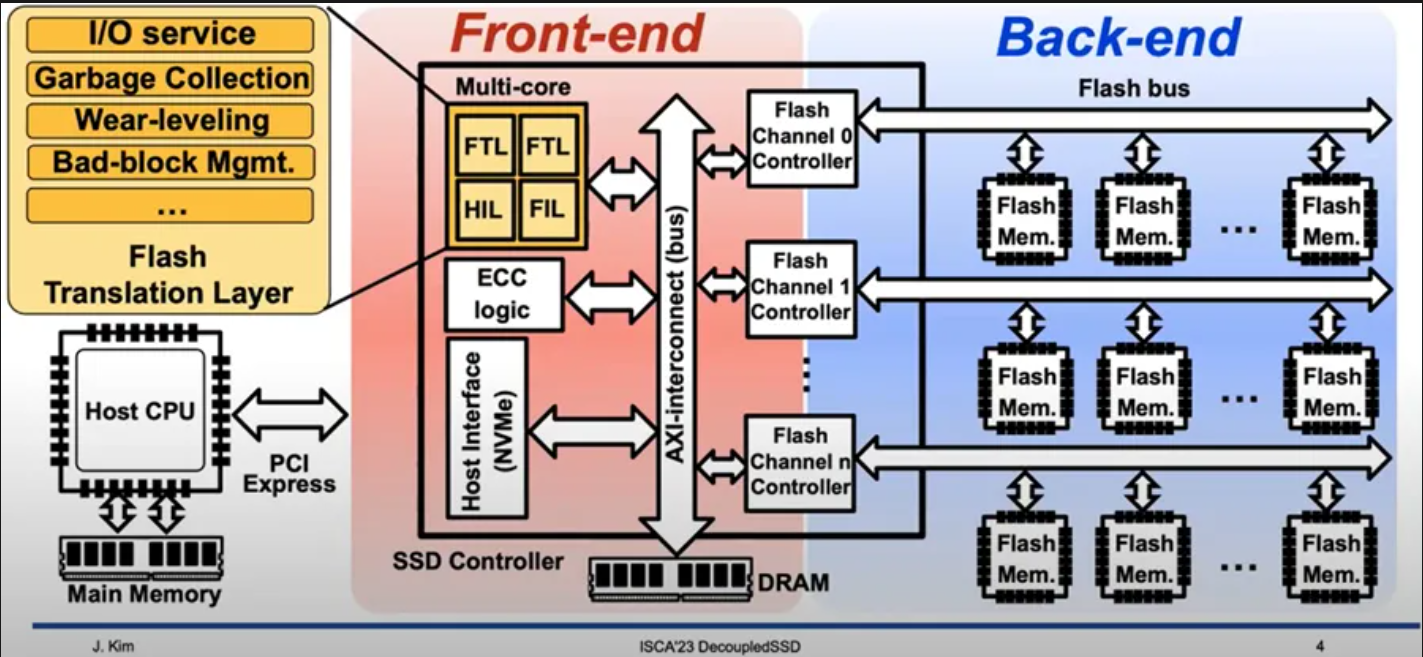
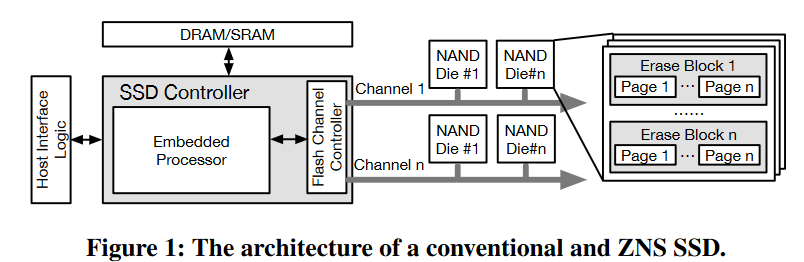
SSD 内部结构
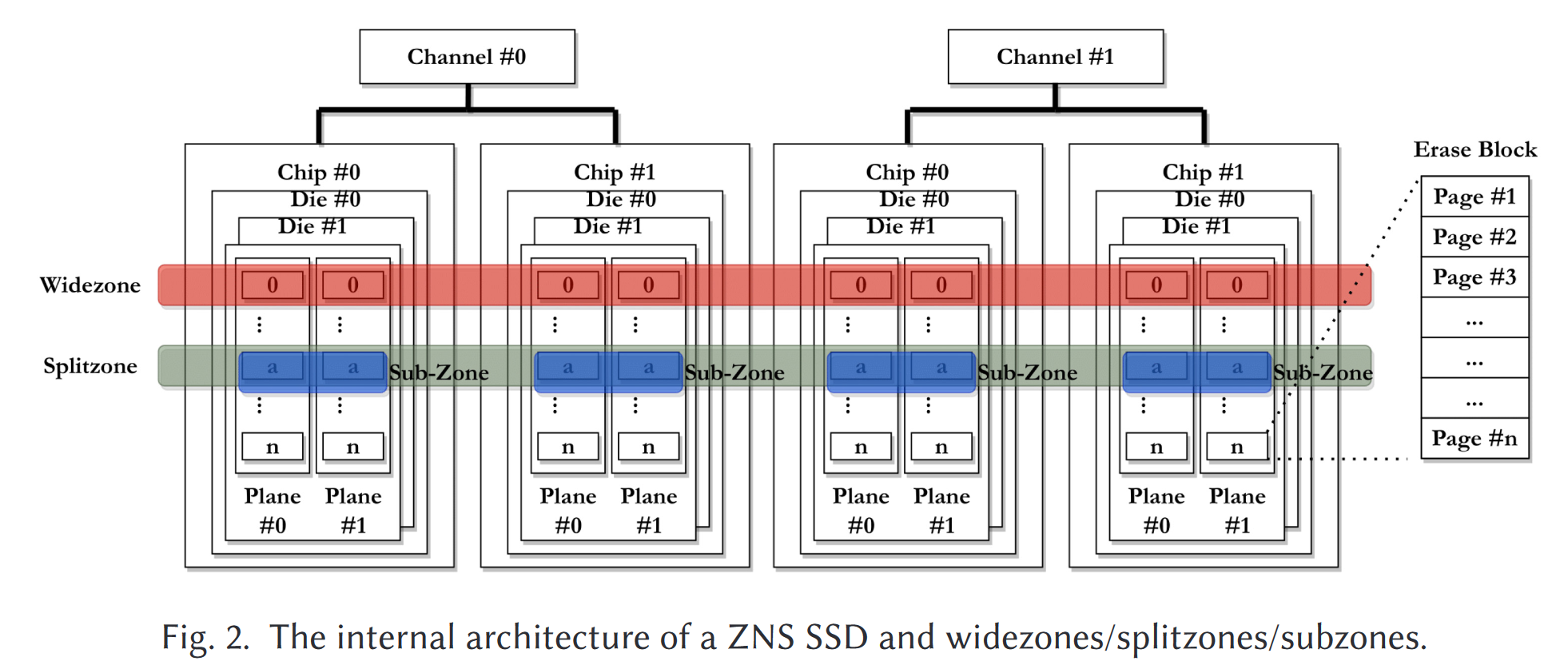
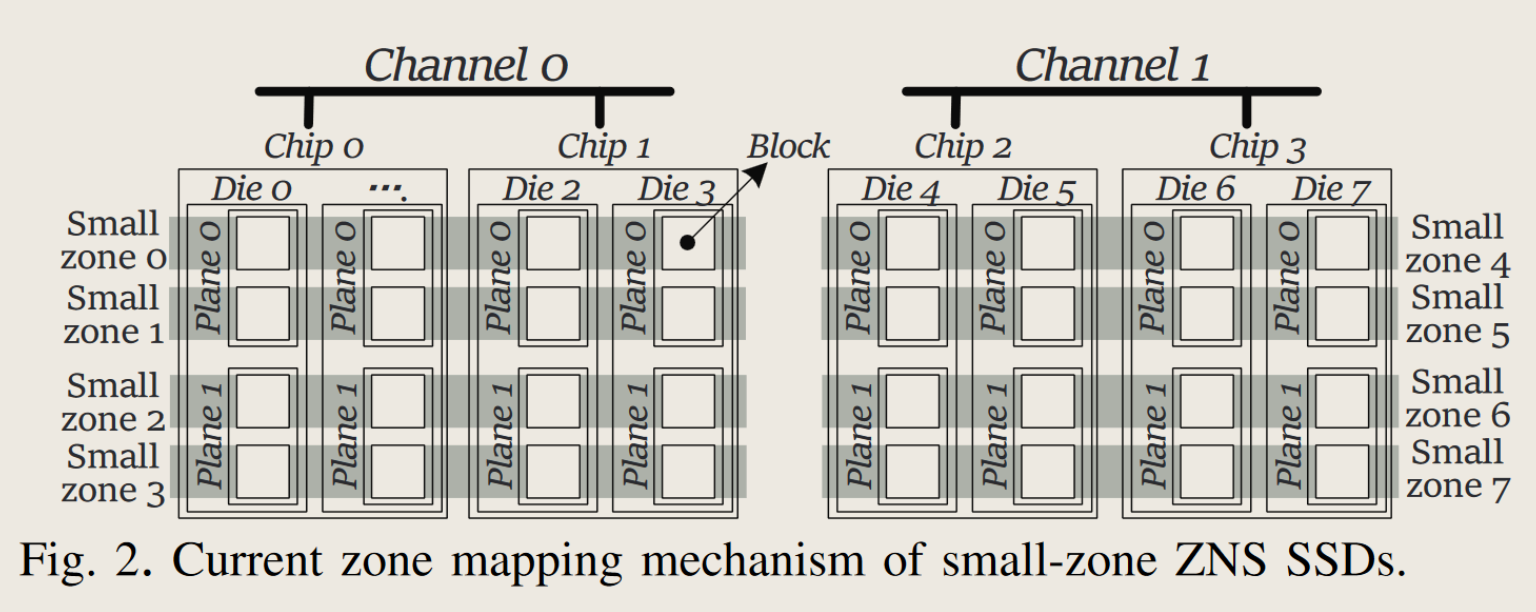
闪存存储采用多级并行架构:内包含有多个channel,每个通道通过闪存总线连接多个闪存芯片,每个芯片内部包含多个晶圆die,每个晶圆由几组plane组成,每个分组由大量的闪存块(如1024个),每个块包含大量闪存页(如2048页),闪存页大小为16KB或32KB
- 晶圆是独立执行闪存命令的基本并行单元,以页为粒度读写,以块为粒度擦除,写入前必须先擦除,并且页面必须顺序写入
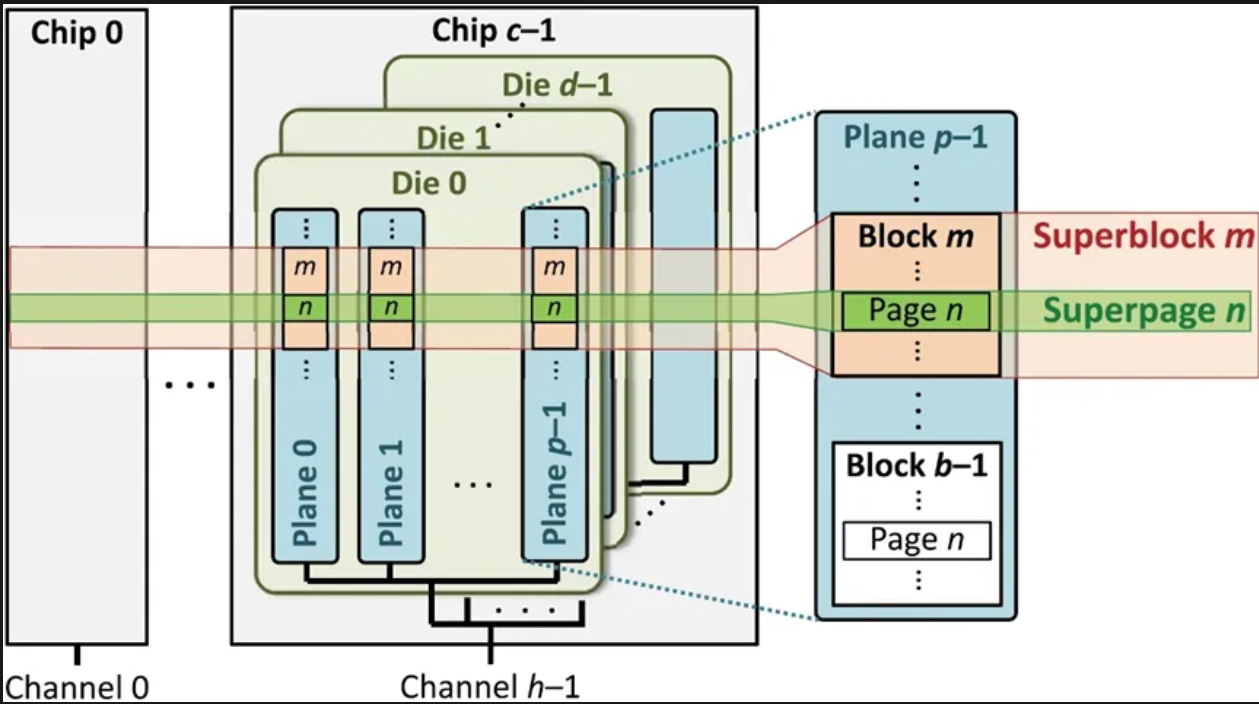
GC与超级块组织
- GC的干扰IO的解决方向
- GC目标与时机选择,如空闲时触发
- 冷热数据分离,降低GC迁移开销
- GC请求调度,如限流和中断抢占GC
- FTL通常将多个闪存晶圆中同一偏移的闪存块组织成超级块,以超级块为单位进行空间分配、写入和GC。可以最大化并行访问、构建RAID保护、降低管理开销
- GC的干扰IO的解决方向
GC时数据迁移包含了读取有效页并ECC解码、缓存DRAM、缓存下刷并ECC编码、写入空闲超级块,期间由于GC会产生大量数据传输,占用前端总线阻塞IO,使得IO请求对总线的占用和带宽急剧下降
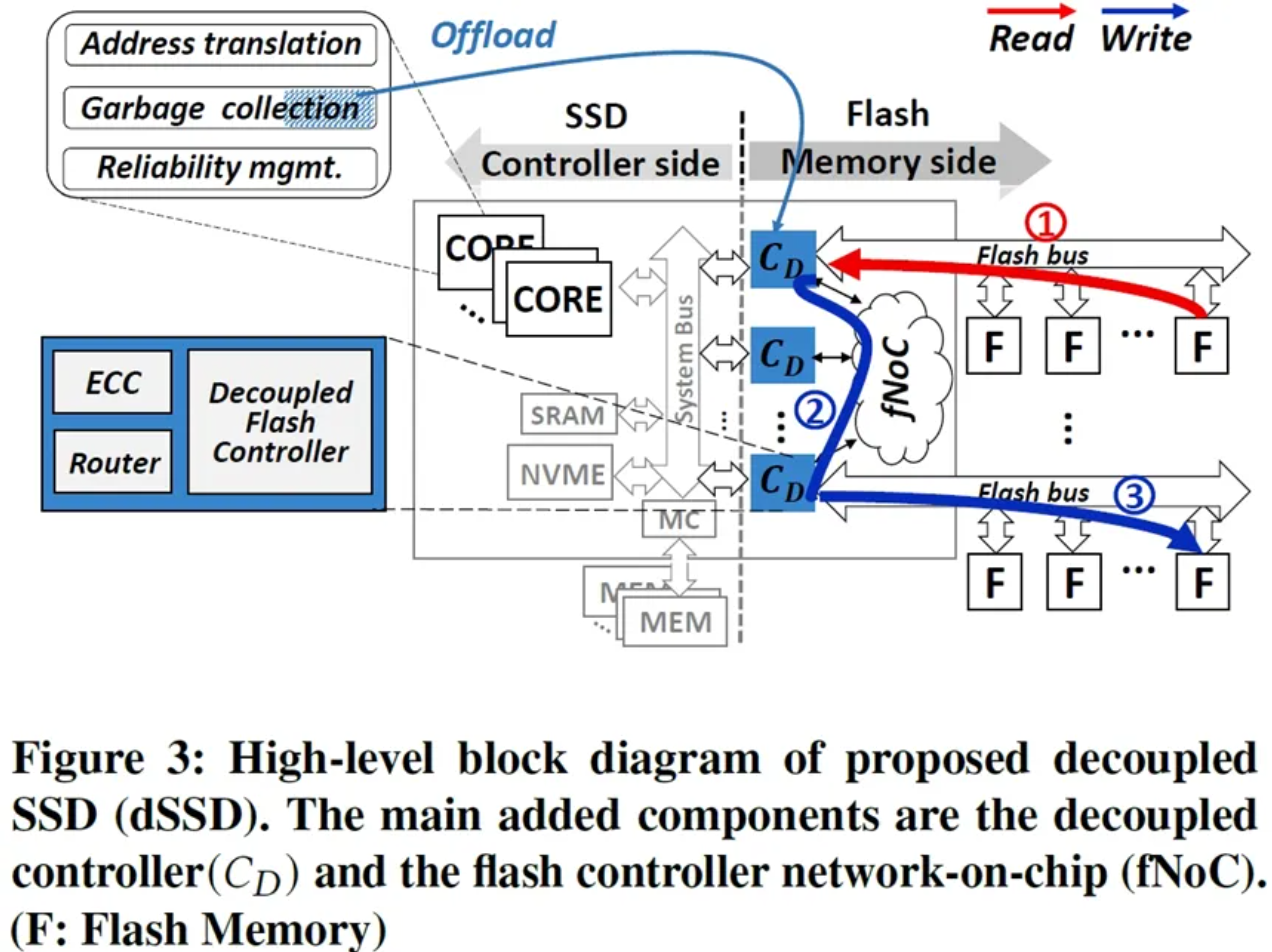
- 前后端分离式Decoupled SSD
- 引入片上网络,每个控制器加入网络路由、数据缓存和ECC的支持,实现后端内存通道见点对点传输
ZNS (ATC 2021)
- 分区存储模型
- zone内部可以随机读,必须顺序写,重写需要reset
- zone的状态:empty、full、opened、closed,处于opened状态的zone受资源限制
- 引入ZNS
- 硬件
- zone size:传统SSD需要通过条带化来保证读写性能和对校验的支持,一个条带通常由16-128个闪存块组成;较大的zone会降低放置自由度但具有更好的数据保护,较小的zone可以保证较低io队列深度下良好的读写性能,
- mapping table:传统SSD使用全相关的LBA-PA映射表(细粒度),但是占用内存(1GB/TB)$\rightarrow$粗粒度的映射表,擦除块级别(zone)维护
- device resource:XOR、内存、电容,将active zone维持在8-32个
- 主控软件
- Host-side FTL:ZNS SSD写语义$\rightleftarrows$应用展现的随机写和就地更新,负责映射转换和GC,还需管理zns使用的cpy和mem,dm-zoned/dm-zap/pblk/SPDK
- 文件系统:传统文件系统时就地写入难以适应zone,f2fs等支持了顺序写入
- 端到端的数据放置:即应用与zns共同协作,实现最佳的写放大、吞吐量和延迟,提出了Zenfs(RocksDB zone存储后端)
- 硬件
- 实现
- 内核支持:内核在内存中维护zone描述符的数据结构;f2fs以segment粒度管理容量,多个segment组成section,section与zone对齐;五种段类型(free/open/full/unuseable/partial)
- RocksDB Zone支持:RocksDB通过文件系统wrapper API管理文件和目录,无法将数据放入指定空间,降低了性能
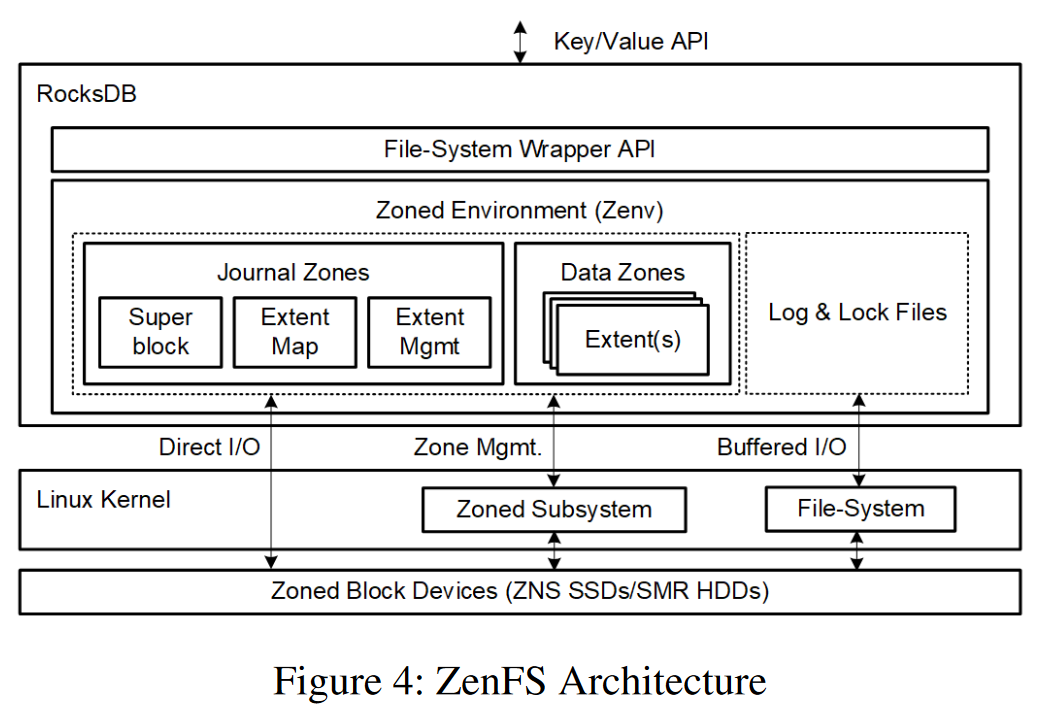
- ZenFS架构
- zone被分为日志zone和数据zone
- extent:数据被写入一组extent中,extent是变长的、对齐块的连续区域,内存中维护extent的分配与释放事件,维护extent-zone的映射,当zone中所有extent被删除时该zone可以reset
- superblock:从磁盘恢复zenfs状态的入口
- Journal:维护超级块、WAL、datafile->zone的映射
- Data Zone中可写容量:只有当文件是可写容量的整数倍时才会实现最佳的空间利用率,zone不会出现空洞;可以设置zone完成百分比,超过则分配zone
- Data Zone选择:尽力而为的算法选择存RocksDB到哪个zone;新的写入直接分配新zone;优先从active zone中分配,当文件的生命周期小于zone中最老的数据(待写数据会在之前无效)则匹配成功,避免延长zone的生命周期;让生命接近的数据尽量放置同一zone中
- Active Zone Limit:ZenFS最少需要三个Zone(日志、WAL和compaction),6-12个活动zone
- 直接IO和缓冲写:SST文件连续且不可变使用直接IO跳过内核的cache;WAL缓冲写

Accelerating RocksDB(MiddleWare 2022):优化数据放置
- rocksDB+ZenFS+小尺寸zone会影响内部并行性导致吞吐量远低于大尺寸zone
- 在写入文件时,小尺寸zone会使得写入的数据分布在多个zone中,比写入单个zone应该有更高的吞吐量
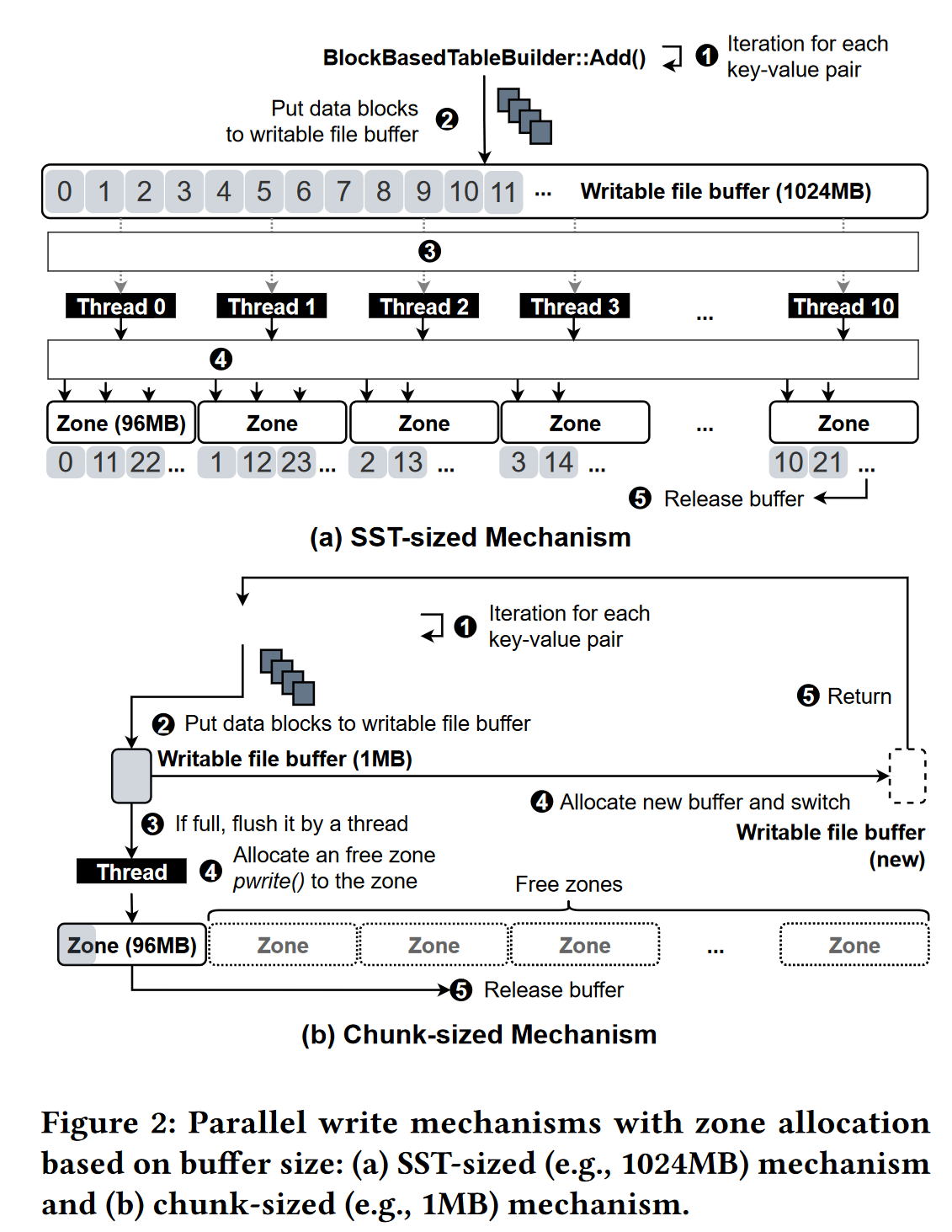
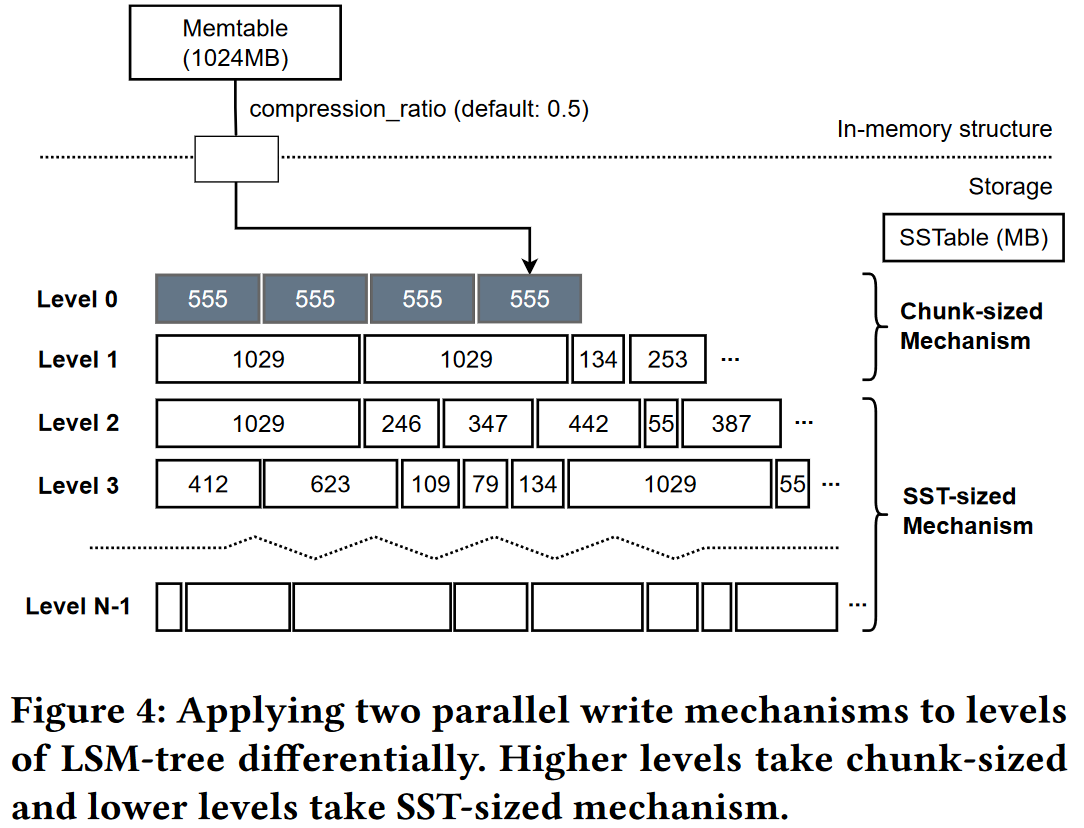
- 并行写入机制:SST-sized Chunk-sized
SST-sized(如1024M) $\rightarrow$ Chunk-sized(如1M),较大的缓冲区大小会影响并行性,选用chunk级别的缓冲区不用等待IO结束直接将数据由单个线程在后台写入,然而可能会导致zone中由更多的未写入空间
- 基于SST级别的zone管理策略–提高内部并行性并减少zone空间浪费
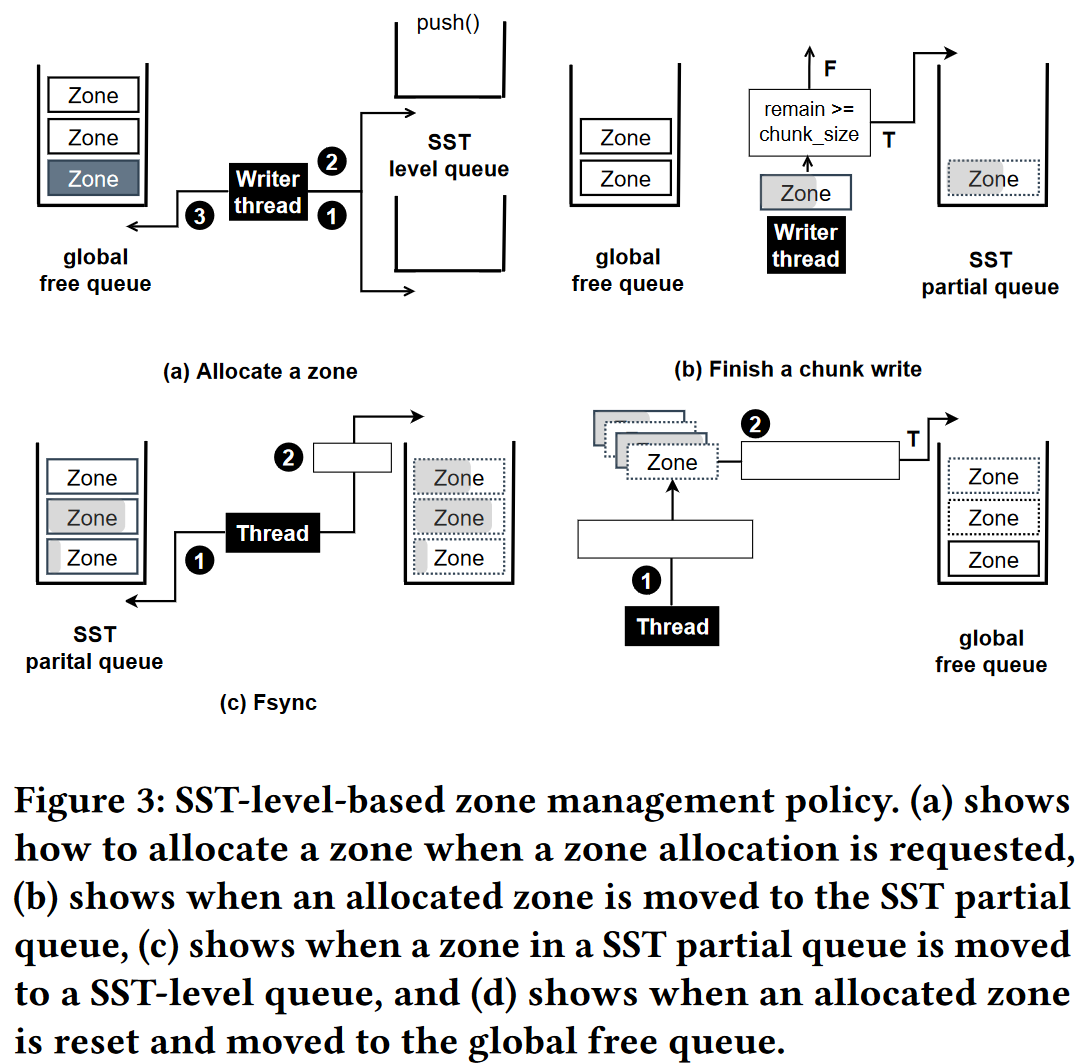
- 全局空闲队列:所有的空闲zone
- SST私有部分写队列:对应SST文件部分写入的zone
- SST级别队列:同一SST级别中部分写入的zone
- 分配请求次序:SST私有部分写队列$\rightarrow$SST级别队列$\rightarrow$全局空闲队列
- 运行时队列维护:
- 从全局空闲队列中申请一个zone$\rightarrow$写入数据后如果remain>chunk-size,则放入SST的私有部分队列,用于后续使用
- 当SST完成写入,将该SST的私有部分队列中的zone迁移到SST级别队列,如果SST被删除并且对应的zone中无有效块则被迁移到全局空闲队列
- 将并行写应用到LSM tree
- LSMtree中,较新层的数据SST大小基本相同,较旧层数据因为compaction导致SST尺寸变化大,所以较旧层更要考虑zone1的空间利用率
- 在较旧层使用基于SST-sized的写入机制,在较新层使用基于chunk-sized的写入机制(图2)
- 并行读机制
- 提升rocksDB的compaction和顺序负载的读性能,从多个zone并行读取数据
- 双buffer机制加速读取
eZNS (OSDI 2023):动态的命名空间和zone管理
背景
- zone可以本分为物理zone(小)和逻辑zone(大)
- 大zone跨越内部所有channel的多个die,通过主机软件控制设备行为灵活性有限,无法适应负载变化,带宽利用率低,对外暴露的zone数目也少,适合少量租户对可用zone数目要求不高的场景
- 小zone只包含一个die,灵活性更高可以支持更多的IO流,具备较小的回收延时
- 静态的分区接口导致zone在配置和初始化之后,最优性能固定,无法使用运行时负载特征,跨区域IO干扰会产生不可预测的IO执行。难点:接口对租户的IO了解困难;额外开发负担;负载的变化使得资源超额配置
- ZNS SSD 内部active zone利用不充分
- ZNS SSD 在内部管理区域分配和磨损均衡,没有强大的隔离支持,并向应用程序公开不透明的视图,从而产生不可预测的性能干扰和I/O的不公平执行。
ZNS SSD 性能特点
- 问题1:条带的动态化配置最大化带宽利用率,足够的active zone保证并发性
- 条带化将数据块划分到多个物理zone上,并行访问
- stripe size 条带大小: 条带中数据最小的放置单元
- stripe width 条带宽度: 处于活动状态的物理zone的数量,控制写入带宽
- 当条带大小与页大小匹配时,达到最佳条带效率;io大小大于条带大小会导致多次连续的die访问;io大小小于条带大小太多会导致带宽利用不充分,例如$4kb \times 8zone \gt 8kb \times 4zones$
- 问题2:放置问题
- 通道重叠放置,不同的zone争用同一通道
- die重叠放置,不同zone争用同一die
- 可以通过一个设备抽象层管理zone布局,维护物理设备的影子视图
- 问题3:租户调度问题
- 单个die的带宽非常有限干扰严重,多个zone可能在一个die上碰撞
- ZNS SSD在缓存溢出时会经历很大的延迟,传统SSD会横跨所有的die以利用最大带宽而ZNS必须输入指定的die使得带宽有限
- 需要了解命名空间和逻辑zone如何共享底层通道和die,区分竞争和协作;加入仲裁调度机制
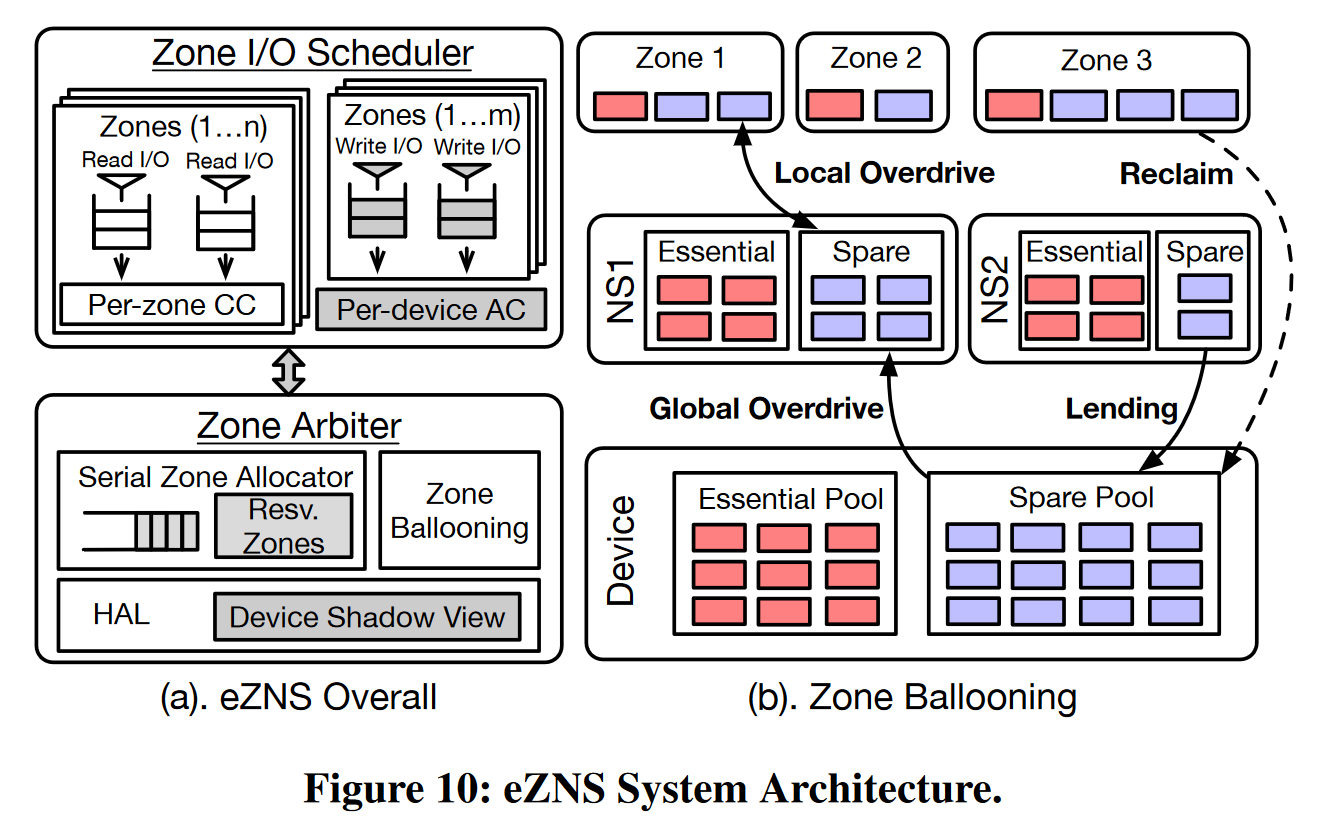
eZNS设计
- 区域仲裁器
- 硬件合约和硬件抽象层HAL
- 一个物理zone只包含一个die上的一个或多个块;最大活跃zone数目为die数目的倍数,并且所有die设计相同的zone;遵循磨损均衡
- HAL:最大的活跃zone数目(与die数目成正比)、页面大小(用于条带化配置)、物理zone大小
- 串行zone分配器:串行分配物理zone条带,不出现die重叠
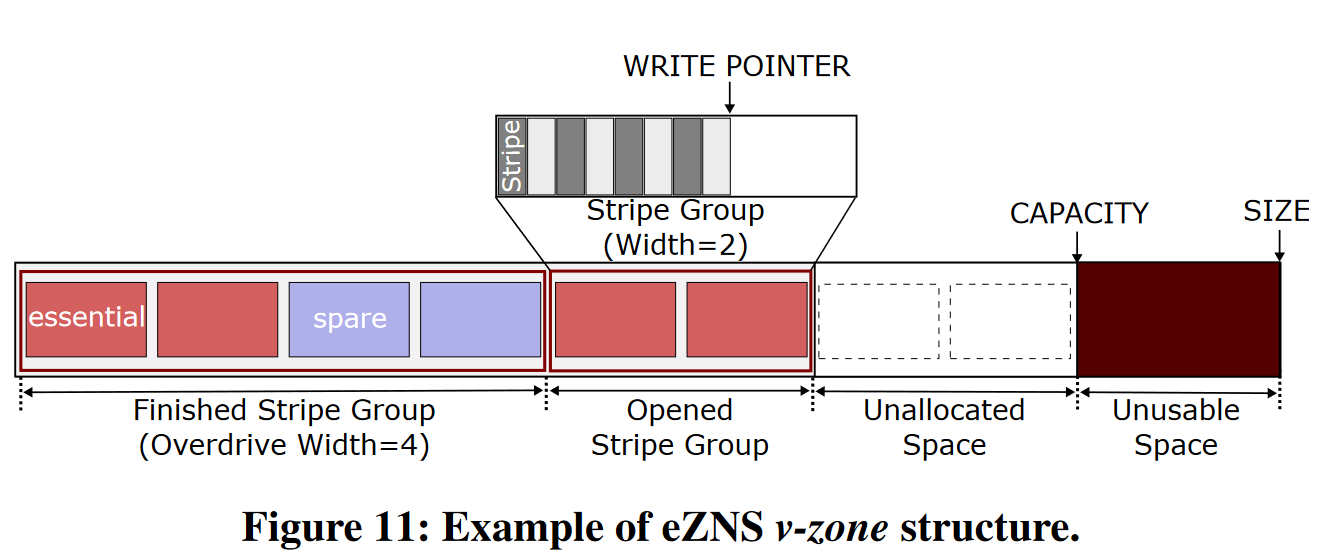
- V-zone:可以自动扩展IO条带配置和硬件资源,大小为2的幂次方
- zone膨胀
- 将zone分为essential和spare两类,初始化时平均分配资源
- 局部过载-zone扩展
- 全局过载-namespace扩展
- 硬件合约和硬件抽象层HAL
- 租户识别的IO调度程序
- 基于延迟反馈的拥塞控制策略:根据延迟控制窗口大小
- 基于令牌的写缓存准入策略:通过连个连续块写入间的最小延迟调整令牌生成率
CAZA (HotStorage 2022):优化zone分配
ZenFS使用基于生命周期的zone分配算法LIZA,将相同生命周期的数据放入同一zone,根据LSMtree中每层的写入频率设置赋予一个生命周期,根据新SSTable创建时所在层级预测其生命周期,但是LIZA未考虑SSTable如何在LSM中失效
ZenFS是RocksDB的后端模块,负责为新的SSTable分配zone,回收zone中失效空间
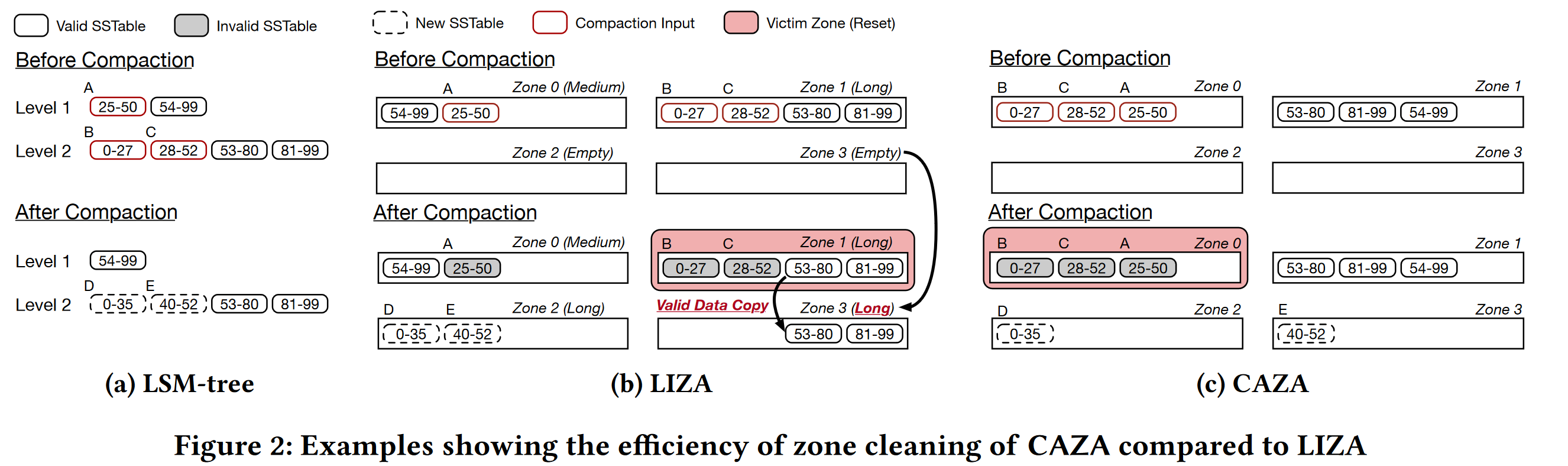
- LIZA存在的问题
- 相邻级别的且有重叠方位的SSTable会因为compaction放置到不同的zone中(b中zone2和zone3)
- Compaction会使得跨zone的不同生命周期的SSTable失效(b中zone A B C),即让多个zone部分失效,增加清理难度
- CAZA
- 主要思想:把有可能同时失效的SSTable(可能在不同LSMtree层级)放在同一个zone上,减少回收时数据复制开销,回收时仅回收无有效数据的zone
- 算法流程:
- L级别要构建新SSTable s时,先搜索L+1层看有键重叠的SSTable构建集合$S_overlap$
- 构建集合Z表示$S_overlap$来自的zone
- 然后按包含有$S_overlap$中的SSTable数量对集合Z进行降序排序
- 从Z中降序分配zone
- 当$S_overlap$为空,则分配空zone;当按Z中分配的zone无足够空间时,也分配一个空zone
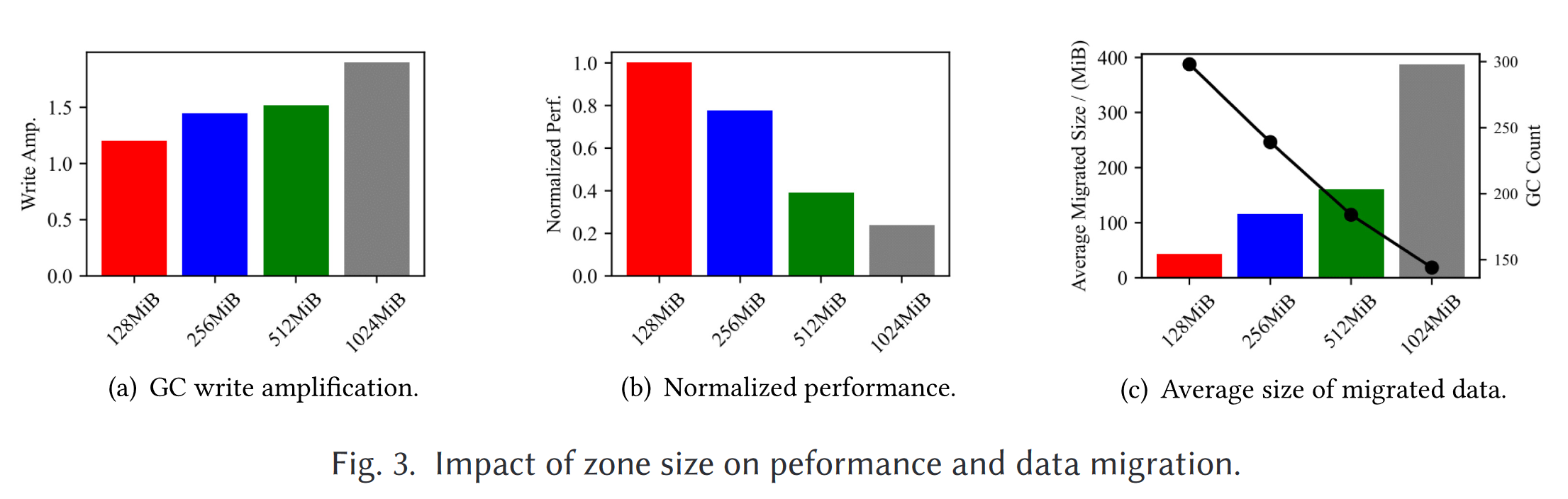
SplitZNS (TACO 2023):GC和数据放置优化
动机
- 大zone对LSMtree性能有负面影响,碎片更多,GC时数据迁移量,消耗过多的IO带宽资源,阻塞前台操作由于迁移时zone不可使用
- 单纯的小zone只使用少量的擦除块,这会减少GC开销,会导致芯片处理IO请求数减少面临IO争用影响性能,由于单个芯片只能处理一个IO,会降低并行度
- 现有方法
- GearDB和Lifetime-leveling compaction使用基于zone的compaction消除GC,写放大严重,延迟高
- GC时LevelDB考虑SSTable查找失败次数,RocsksDB考虑SSTable的age和重叠率
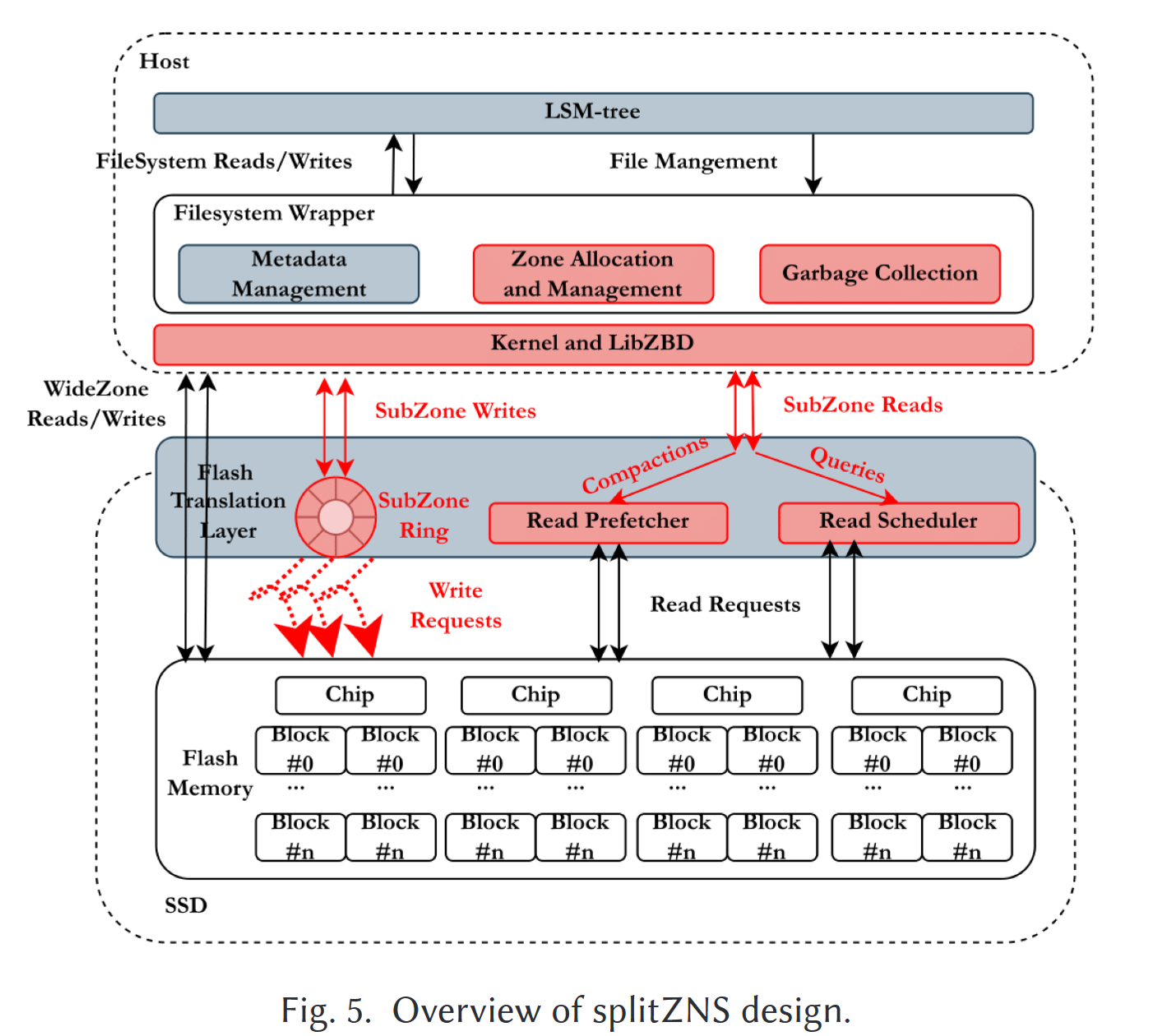
设计与实现
- splitzone/subzone是在数据迁移和并行性利用率间的权衡
- 在较新的level上使用widezone和基于生命周期的数据放置,在较旧的level上使用相对更小的subzone
- 基于周末周期的数据放置策略在在较新level上有效,在较旧level上不准确
- 小zone不佳性能会导致compaction变慢,导致写入停滞
- zone 分配器
- 为具有相同生命周期的SSTable分配同一个widezone,较新层的level上需要预留足够的空间来接收memtable的刷入,因此选用widezone
- 为了最大化并行性,分配subzone时应贪婪选择使用量最高splitzone,平衡每个芯片管理的subzone数量,减少io干扰
- 设备端分配器采用轮询方式分配芯片,主机端与设备端协调,感知内部并行性
- 其他用于加速的设计
- SubZone Ring
- 在每个芯片上实现一个FIFO buffer,缓存写入subzone的数据,然后同时将尽可能多的buffer同时输入zone中,使得对subzone的写入等效于对widezone的写入(前提是充分利用所有芯片)
- 通过一个辅助环形数组记录实际需要写入的地址,并提供zone的实际写入指针来加速涉及缓存区数据的读操作
- 读预取器和读调度器
- 对subzone的读请求分为前台的查询请求和后台的compaction,compaction可能阻塞查询导致较高的查询尾延迟
- 通过引入一个读指针记录上次读取位置,判断是否是顺序读写,顺序读写则被认定为compaction
- 每个chip维护一个IO优先队列,随机读写请求高于顺序读写请求
- SubZone Ring
WALTZ (PVLDB 2023):WAL写入优化
动机
- 问题: WAL会带来频繁的小写,降低写入吞吐量形成扩展瓶颈;多线程环境下WAL可能因为写入阻塞而增加延迟
- 现有:
- RocksDB的batch-group write进程,通过在多个待写入worker中选出leader,收集所有待写入记录并并写入;该方法没有降低为延迟,会增加记录写入等待时间;ZenFS没有解决这个问题
- zone append为增加NVMe接口队列深度并保证其写入顺序提供了保障;zone append命令通过指定数据和写入zone,而不需确切的LBA(由设备决定并返回给host),使得增加队列深度不会影响尾延迟并提高吞吐量
- 本文方案:使用append command来优化WAL记录的写入尾延迟
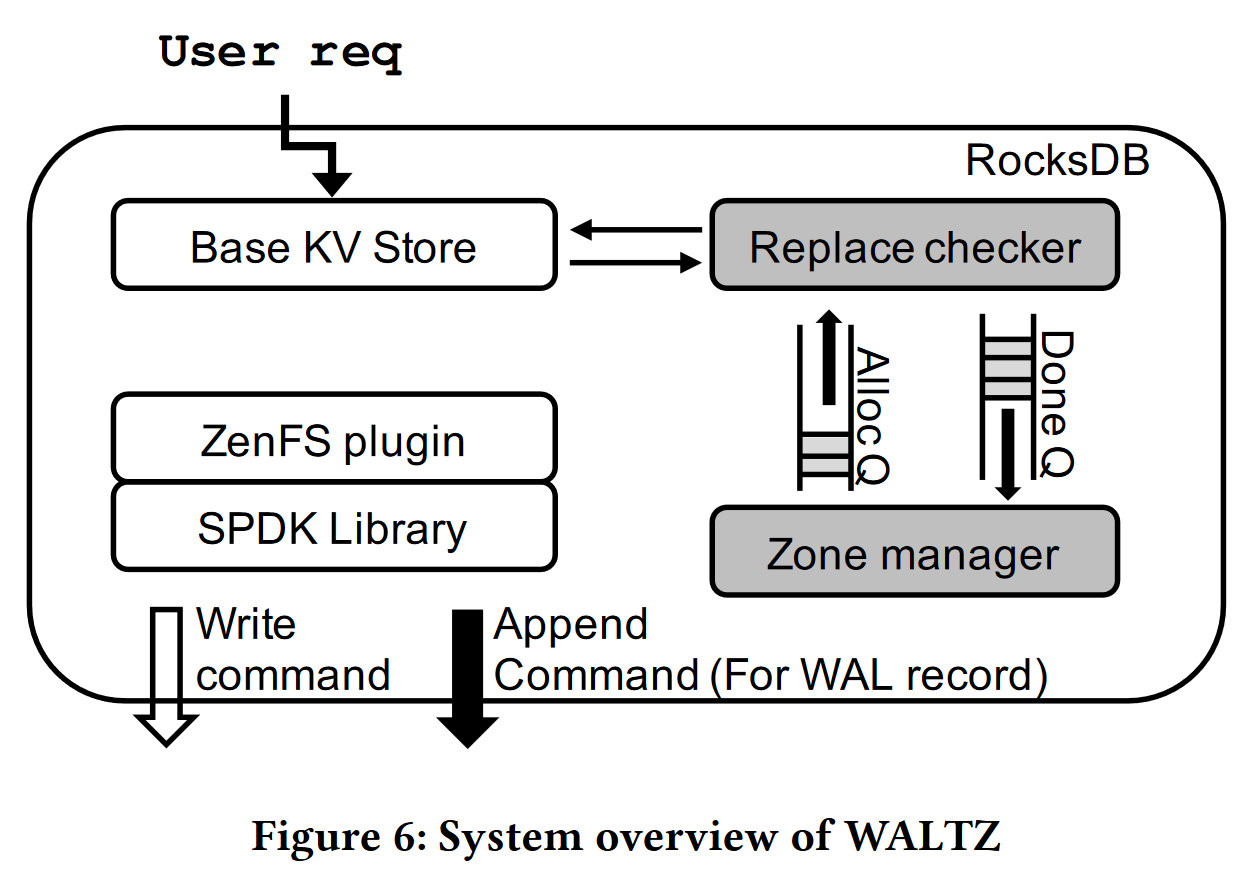
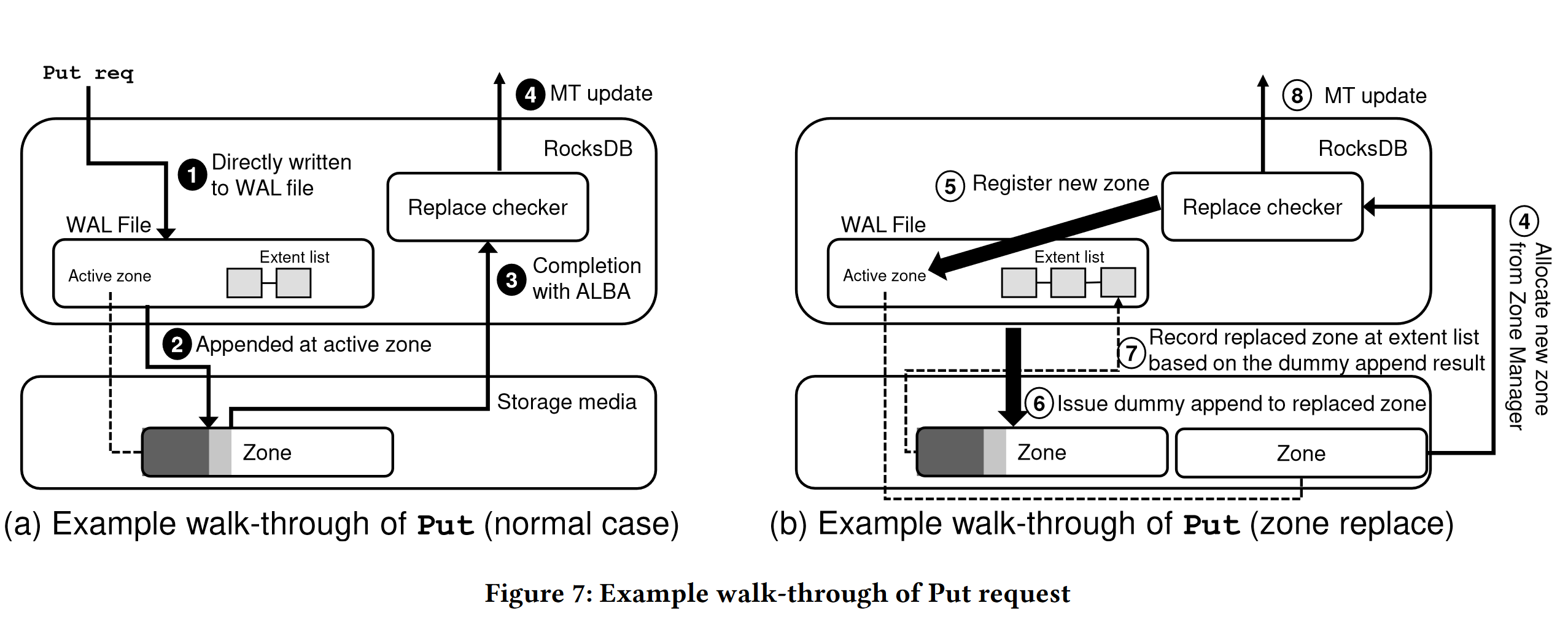
设计与实现
- 系统架构
- replace checker:决定是否需要为WAL写入替换active zone,并通知工作线程
- zone manager:负责在工作线程为WAL请求新zone时预留zone,接管关闭中zone的关闭和完成操作
- Alloc Q、Done Q
- 设计
- 写路径:跳过rocksDB的BatchGroup操作,直接将所有工作线程的写入请求追加到WAL中,完成后立即更新memtale
- 替换检查器:
- 缓解因为zone空间不足导致append命令错误响应和重试导致的尾延迟上升;WALTZ通过计算剩余空间是否小于阈值决定
- 替换线程在替换zone时,工作线程继续将记录写入原来的zone(需要在替换后相应修改ZoneFile元数据),减少等待时间,只有在为完成替换且写满时才会触发重试
- 虚拟追加:
- 使用zone append命令用于检索写入指针的最新位置,用于替代延迟较高的zone report命令(70x)
- Zone分配
- ZenFS中基于生命周期的zone分配方式会因为逐个轮询而导致延迟增加,尤其是small-size zone的情况下
- zone manager后台线程保留两个zone(可能出现两个zone同时写入WAL的情况)用于快速响应分区替换
- ZoneFile元数据管理
- 仅在分区替换时更新zonefile元数据
- 恢复时也使用zone append命令获取写入指针位置(由于lazy manage导致故障时元数据未更新),由于ZoneFile会独占整个zone,只需查询写入指针位置即可恢复整个zone内部WAL
IS-AR (DATE 2023)
- 动机
- ZNS在GC过程中,需要将驱逐zone中有效数据读入到host的buffer中再写入到新zone中,有不必要的端到端数据迁移开销
- 由于ZNS内部的zone-block间映射是预先配置好的,GC带来的块到块迁移开销也很大
- 实现
- IS(内部数据迁移):Zone_MD命令实现zone内部的数据迁移
- AR(地址重映射):
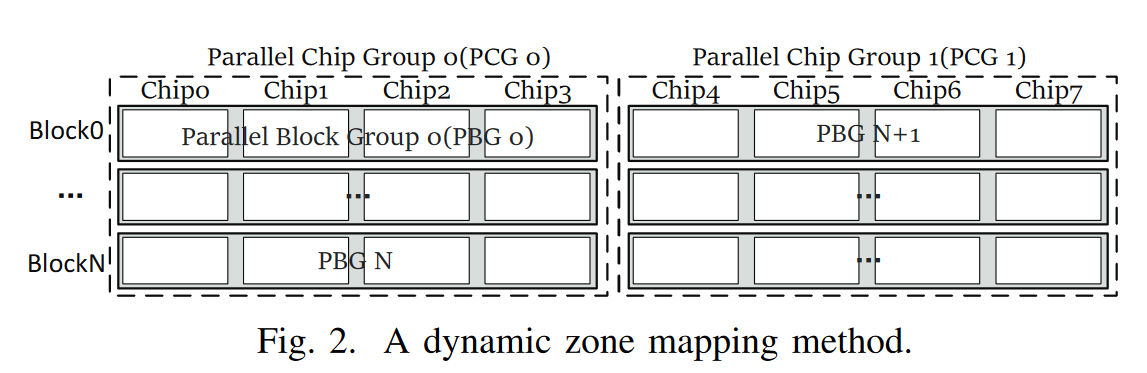
- 将芯片编组为PCG,将内部相同偏移的块编组为PBG,提高并行性;PBG为重映射最小单元,分配zone后将PBG动态分配到zone中;当zone中空间利用率大于指定值时执行重映射,否则直接重写
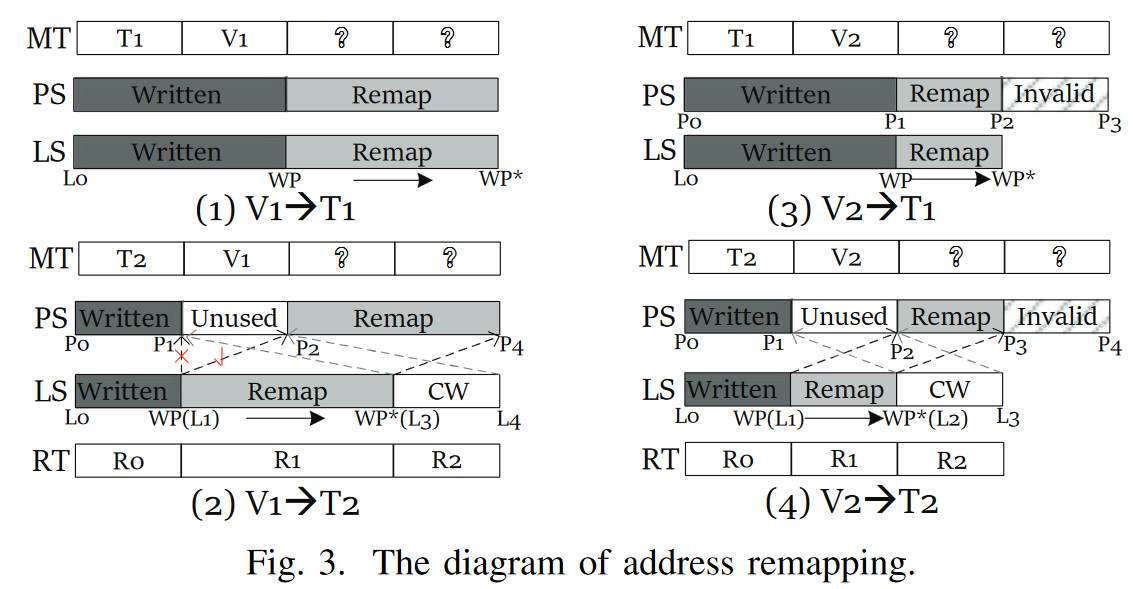
ZNSKV (ICCD 2022)
动机
- LSM树Compaction和GC存在双重写放大问题,现有研究有从
- LSM-tree角度优化数据组织与存放
- 减少SSTable参与合并次数:虚拟SSTable延迟Compaction等
- KV分离,将KV分开管理存储,减少GC开销,有范围查询、一致性等问题
- 根据数据寿命优化数据布局
- 数据放置
- 基于数据冷热的布局,但对于追加写入的日志结构系统以LBA估计冷热不准确
- 基于流
- 基于寿命布局:将SSTable写入一个超级块,避免迁移;ZenFS将SSTable与Zone大小对齐
- GC:基于贪心、磨损、成本效益来选择回收的SSTable;将热数据写入即将擦除的块上;设备端迁移;
- 数据放置
- LSM-tree角度优化数据组织与存放
基于传统SSD的键值存储系统中,底层设备与上层应用之间存在语义隔离,导致键值存储系统存在功能冗余和优化冲突等问题。需要提出寿命预测更加准确,垃圾 回收开销更小的新方案。
设计
- 文件寿命预测
- 文件类型决定了文件寿命
- 元数据(RocksDB中的MANIFEST、CURRENT)、WAL的寿命极短,元数据每当SSTable被改动都会更新,而WAL再键值对持久化后被删除
- SSTable寿命由上层往下层递增,10s~1000s
- 细粒度区分同层SSTable文件寿命,文件
- 文件类型决定了文件寿命
- 数据布局
- 一般以ZoneFile为粒度管理键值存储文件,一个ZoneFile对应一个SSTable或WAL
- 文件系统维护Zone容量信息;提供一个Zone信息传输接口,维护所以zone-extent容器,提供有效数据占比
- zone分配,贪心选择生命周期差值最小的;数据缓冲去用于数据暂存和对齐到LBA;为WAL保留一个zone用于快速写入
- Compaction-GC
- 思想:合并排序的同时完成GC操作;对有效数据较多的分区GC开销较大,且在迁移的不久后可能发生合并排序导致迁移数据无效
- compaction文件选取算法
- CompactionPri(有合并排序写放大决定)$ = -S(Filesize)$:选择compaction总文件大小最小的一组文件,读取的数据最少
- GCPri(由GC写放大决定)$ = U(GP)$:选择总无效数据最多的一组,可减少的GC数据读写量
- $Compaction-GCPri = U(GP)-S(Filesize)$,选择整体写放大最小的
- $𝐴𝑑𝑎𝑝𝑡𝑖𝑣𝑒𝑃𝑟𝑖 = 𝑘 ⋅ 𝑈(𝐺𝑃) − 𝑆(𝐹𝑖𝑙𝑒𝑠𝑖𝑧𝑒)$,k来自适应调整清理速度
- 选择性数据迁移
- 孤寡文件:与下层SSTable文件无键重叠,只能通过GC回收
- 多子文件:在下层与其有重叠范围的文件过多,Compaction写放大过大
基于分区命名空间固态盘的高效LSM-tree键值存储系统研究(2022)
动机
- 基于LBA访问频率的冷热数据识别与放置失效,无法被上层识别
- ZenFS无法识别数据列族信息导致数据布局效率低
DZR (JSA 2024)
基于键范围(key level)的分区分配
- CAZA:同一分区中key范围可能重叠但compaction时间接近,没有考虑活动分区限制,没有考虑多线程并行compaction,不是可插拔方案需要修改rocksdb
基于级别(level)的分区分配
- GearDB: 一个分区只存一个级别SST,一个分区由多个这样的分区组成,这些中只有一个处于可写状态,但是由于只有一个可写阻碍了多线程compaction
- lifetime-leveling compaction:强制低级别SST参与compaction
动机
- 压实局部性 Compaction locality:MemTable Flush和L0->L1并发执行锁定分区,LONG和EXTREME文件交替生成,分区中出现局部性时,压缩线程会锁定与分区中同时创建的压缩输出文件具有相似生存期的活动区域
- 多线程环境中,ZenFS的竞争避免策略无法分配相似生命周期的分区,L1级别出现局部性,会导致该级别生成的SST划分到EXTREME分区中,会导致写放大恶化
设计
- 原始ZenFS中WAL与SST混合放置,DZR将WAL放入单独的预留分区中
- 是由GearDB的思想,将zone分为zone group,一个group里只放一种lifetime的SST
- 通过zone group累计阻塞时间描述压实局部性,根据局部性情况重新分配各zone group的活动分区数
Lifetime-leveling Compaction(HotStorage 2022)
LL-compaction 动机
- LSM-Tree中写入与删除顺序的不匹配导致写放大
- 不同级别SST位于同一个zone中
- Compaction的上层驱动性,有可能导致没有重叠范围键的SST被跳过(long lived)和刚被生成的SST又被删除(short lived),短期SST会造成空洞导致写放大
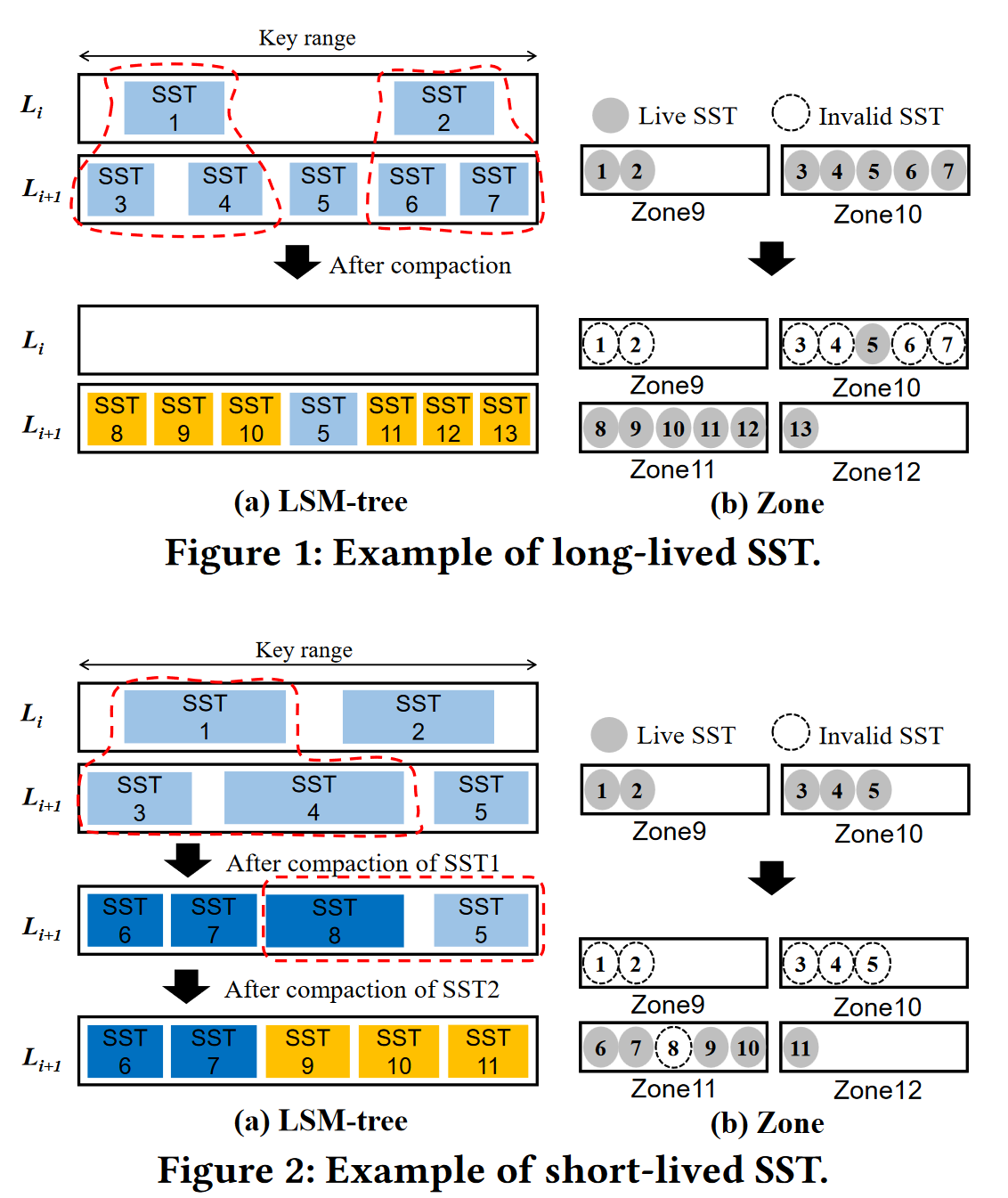
- 传统的Compaction算法的写空间放大问题
- 长生命SST会导致分区因为少量有效数据无法被reset
- 短生命SST是由于相邻compaction选择文件的重叠而使得新增SST不久后被删除,会造成分区内部空间空洞,并增大写入流量
- 空间放大–写放大的trade off
LL-compaction 设计
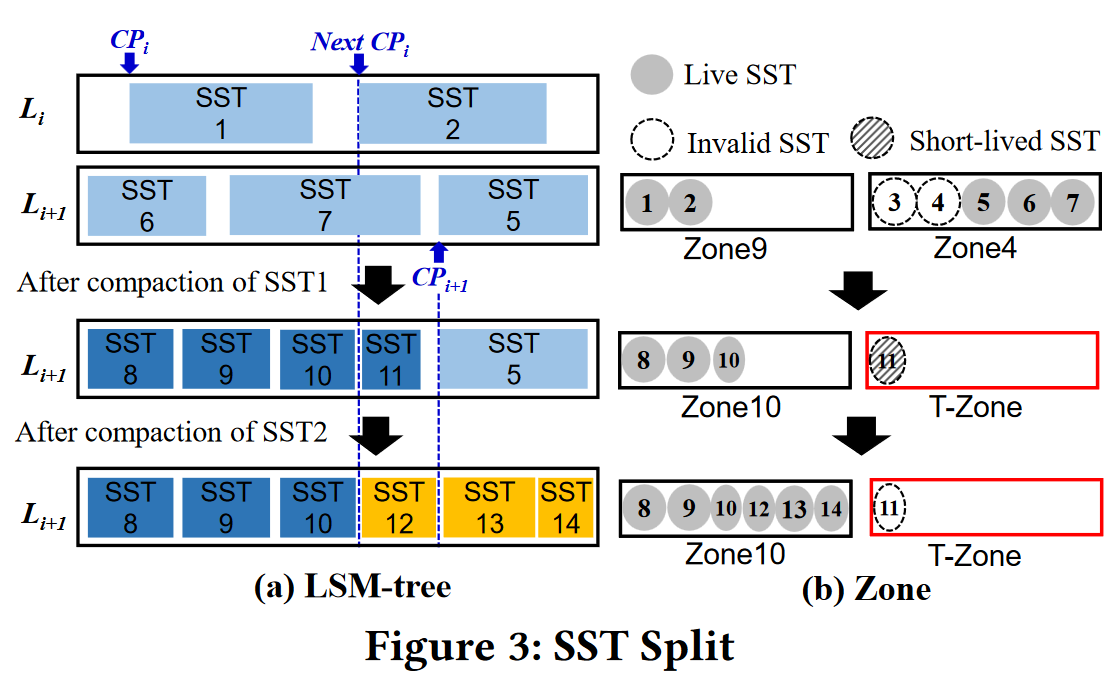
- 设计思想
- 为每个级别的SST分配专用分区
- 为了减少长生命SST,强制压缩Li中cp与下一cp之间所有SST
- 为了减少短生命SST,使用切分和T-zone来减少短生命SST数据量
- 切分:新生成的SST与next CP有重叠,则从重叠开始处切分SST并把后部放入T-zone
- 切分后新生成的SST需要更新下一级SST的CP
LifetimeKV(ICCD 2023)
背景
- 压实操作中$l_i$层SST的选择,选重叠率最低的
- $score = 1024 * \frac{size(oSSTs)}{size(vSST)}$
- vSST:$l_i$层候选SST,oSSTs:$l_i+1$层中与vSST有重叠的SST的集合
动机
- 现有基于级别的SST生命周期推测不准确,级别越高分布越广泛,导致GC开销大,吞吐量降低
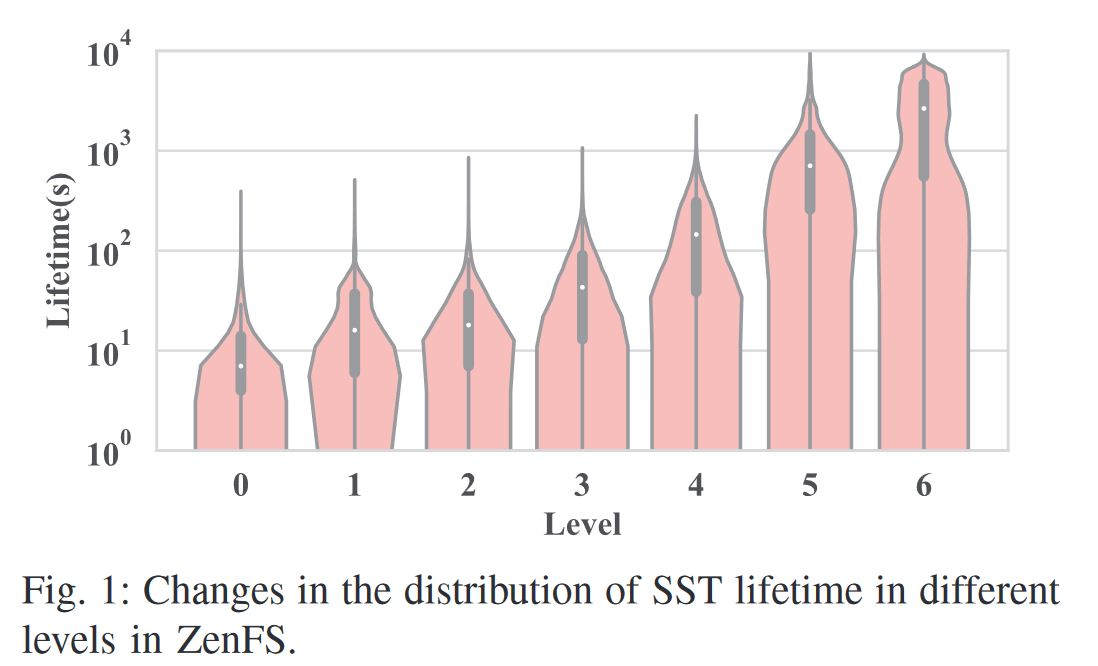
- 存在短寿命SST文件,刚被创建又因为下一次Compaction而被删除

设计
- 范围压实
- 选择完$l_i+1$层中sst后,在看中在$l_i$中是否有与选择sst有重叠的,将重叠部分key的加入merge,并让其失效即修剪(sst的大小不变)
- 修剪sst操作会使得该sst参与压实概率(重叠率)降低,所以可能使得生命周期被延长
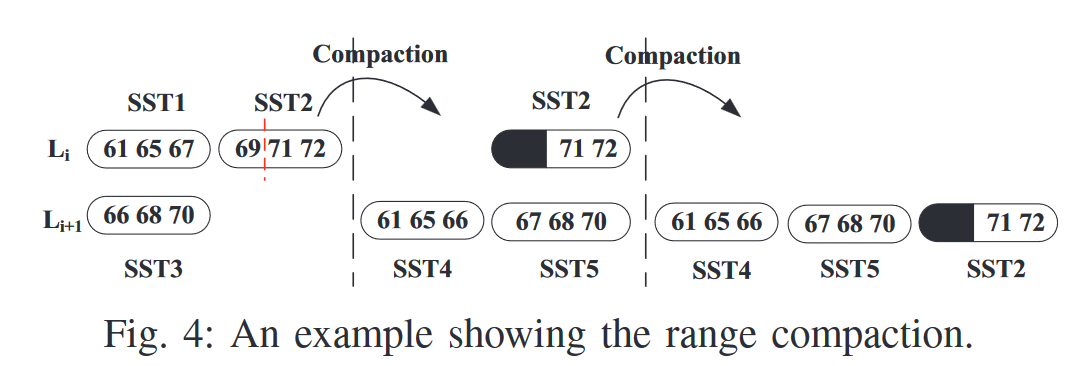
- 驱逐SST选择-基于重叠的SST Overlap-Ratio-Lifetime Victim SST Selection
- 优先选择生命周期长的SST,使得分区内SST生命周期平衡;一次压实,$L_i$中SST主动失效,$L_i+1$中SST被动失效,被动失效SST远多于主动失效
- $L_i$层某SST生命周期长,其$L_i+1$层中与之重叠的SST也会因为长期不参与压实而生命周期长,通过选择$L_i$层SST生命周期长参与压实,使得他们都失效
- $score = 1024 * \frac{S(oSSTs)}{S(vSST)} - \alpha * LT(oSSTs)$
- S总大小,LT平均生命周期
- 优先驱逐$L_i$SST原则:$L_i+1$中与候选SST重叠的SSTs,平均生命周期最长的
- 通过增加LSMT写入量使得同一级别内SST生命周期接近,减少未来GC开销
- 其他细节
- L0和L1混合放置在一组分区中,其他级别各对应一组分区放置,WAL和元数据、数据分开放置
- 预留两个zone防止极端情况下GC
ZoneKV (DAC 2023)
ZoneKV动机
- ZenFS将SST写入大于其生命周期的分区中,使得不同生命周期的SST放在同一zone中,意味着同一zone内SST有着不同的更新频率,导致zone中失效数据多,空间放大高
- 基于level的生命周期预测不准确,一次压实涉及的$L_0$和$L_i+1$中SST具有同样的生命周期
ZoneKV设计
- L0与L1一起放置;一个级别SST分片到多个zone中
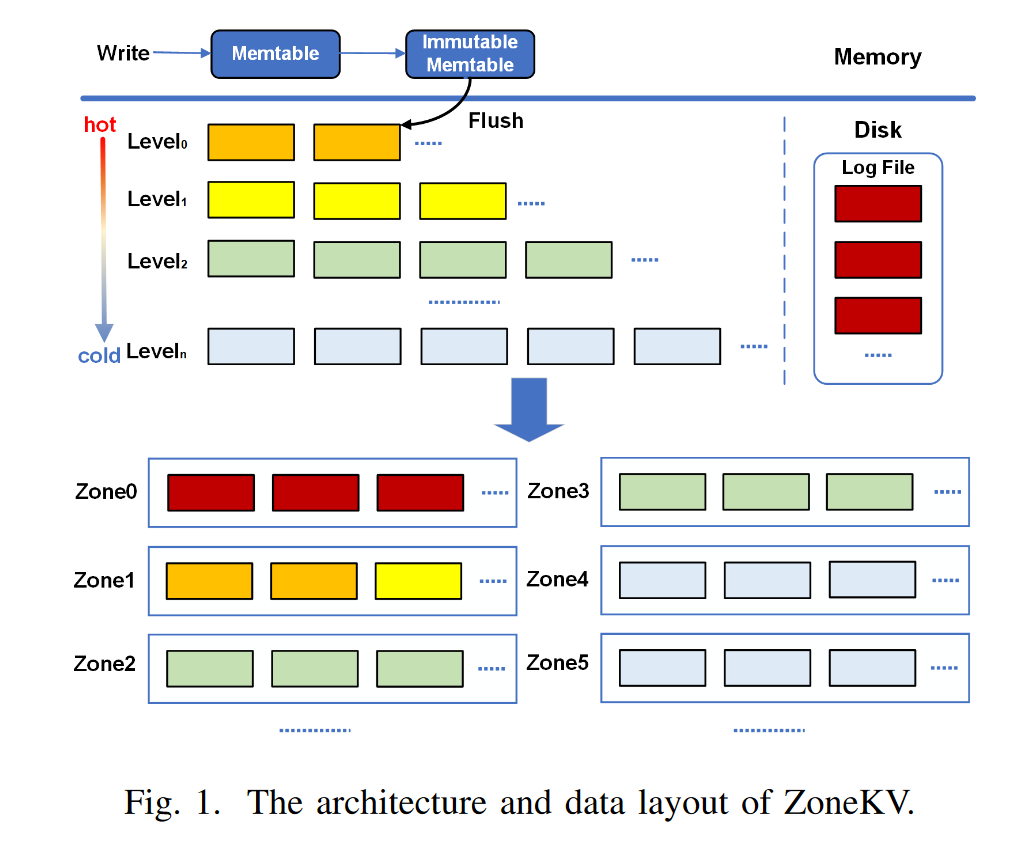
- 尽量把SST放在与之什么周期相同的zone中,如果没有则分配空分区,如果没有空分区则放到生命周期大于SST的分区中,如果都没有则随机放入一个未满分区
- 生命周期由level决定,WAL为-1,L0和L1为1,其余$L_i$为i
FlexZNS: Building High-Performance ZNS SSDs with Size-Flexible and Parity-Protected Zones
背景与动机
将逻辑分区与闪存块组flash block group对齐,消除GC;FBG包含多个芯片上偏移相同的闪存块,并构建芯片级RAID条带
问题1:较大的逻辑分区会使得GC开销较大,通常会根据数据生命周期和热度将其写入到不同的GC单元中;然而分区较大增大了分离不同热度数据的难度
设计1:扩展ZNS接口,使得用户可配置分区大小,往小分区中写入热数据,大分区中写入冷数据,以减少GC
问题2:RAID保护机制提供芯片数据保护,但是为了适应奇偶校验存储开销和不规则的闪存块大小,使得zone capacity小于zone size;当zone大小改变其应用程序的可写空间也会发生变化
设计2:将zone capacity与zone size保持一致,将存储管理的复杂性转移(?)至SSD;将奇偶校验与数据存储解耦,将SSD分为数据区域和奇偶校验区域;将不同大小的分区映射到多个的超级块上,不与存储奇偶校验的超级块重叠
观察
- 大分区会导致不同生命周期数据混合,使得GC的数据迁移开销大
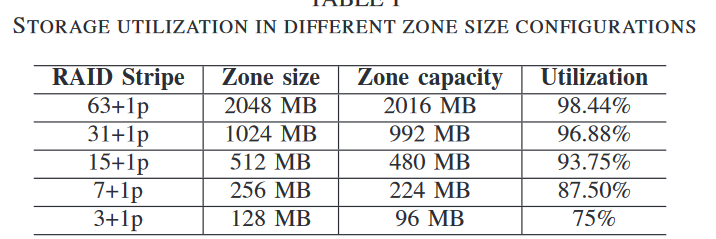
- 小分区会导致可用空间下降,空间利用率降低;并且会使得GC频繁;
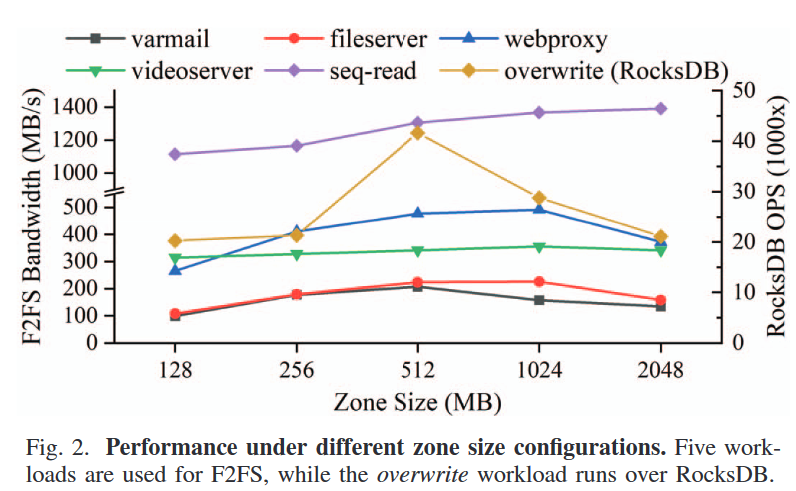
- $<= 512MB$, 分区太小导致分区内芯片并行性不足,访问速度慢性能不佳
- $>= 2048MB$, 分区GC开销变大影响性能(除seq-read外,因为顺序读无GC)
系统设计
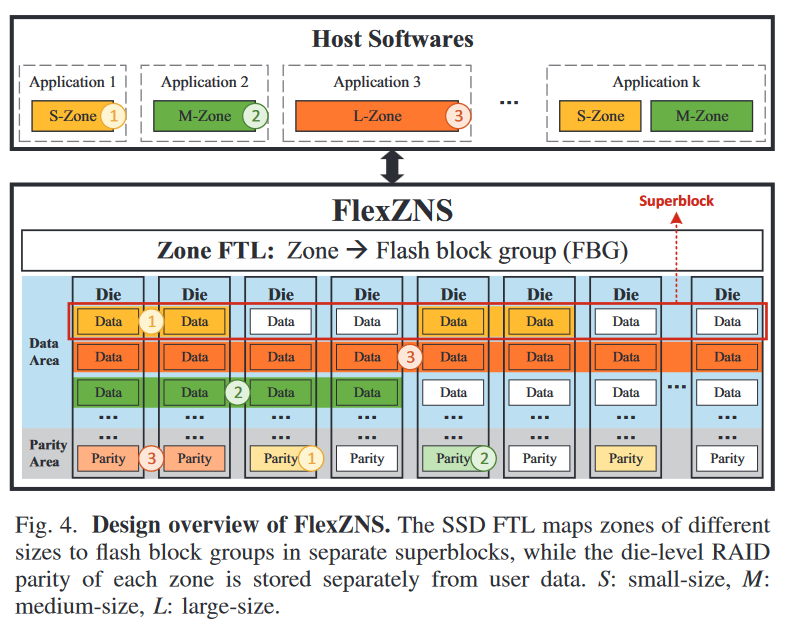
- 解耦数据与校验,将SSD中超级块分为数据区与校验区
- Zone Capacity管理:增加NVME命令zone_format设定zone参数
- Zone Map
- Data Mapping: 动态分配,初始化时确定FBG的数目
- Parity Mapping:静态分配,在zone_format初始化时确定好,先大后小地为FBG分配校验区
Prophet: Optimizing LSM-Based Key-Value Store on ZNS SSDs with File Lifetime Prediction and Compaction Compensation (MSST’24 B)
- 基于Flush/Compaction的次数为时间尺度,标定生命周期
- GC-free模式的I/Os是普通模式的1.6倍,所以GC时仅对未来可能Compaction主动进行该操作
Overlapping Aware Zone Allocation for LSM Tree-Based Store on ZNS SSDs (ASP-DAC’24 C)
- 在分区分配时,除level外还同时考虑待写入SSTable与相邻层的重叠率
Para-ZNS: Improving Small-zone ZNS SSDs Parallelism through Dynamic Zone Mapping (DATE 2024)
para-zns工作介绍
Para-ZNS同时关注芯片级并行性和平面并行性, 使用动态的分区映射模式
- SplitZNS / eZNS /等, 开销较大, 只考虑了芯片级并行性, 并且场景受限
- 设备端可以轻松获取分区映射信息, 可以通过将block从不同芯片映射到开放分区以提高平面级并行性
para-zns提出背景
- 利用率建模: ZNS Zone的状态转换机制反映了分区的使用情况, 结合设备端的zone-die映射, 可以计算/预测die的利用率
- 分区映射模式:
- 小分区ZNS只用到了部分die级别的并行性, 有很多工作着眼于主机端软件优化, 使得尽可能多同时写入非冲突区域(映射到不同die的分区)
- 问题1: 主机端无法看到zone-die的映射关系, 导致主机端并行性提高但开销也高
- 问题2: 当然的映射机制只到了die级别, 忽略了plane级别的并行性, 由于die内部不同plane的block被分散映射到不同zone中, 这让host很难通过die获取zone-plane的映射
- 问题3: 利用平面并行性需要使得die的不同plane的同一地址同时执行同一操作
- 所以, 设备端优化不可避免
para-zns动机
- CG检测冲突zone group, 并优先执行来自不同冲突区域组的I/O请求,以提高并行性; 通过向两个zone发送页面大小的请求, 对比两组带宽
- 动机1: CG方式开销很高, 且CG方式需要足够多的非冲突区域组, 来利用并行性
- 动机2: 平面级利用率很低, zns ssd缺乏保证die内平面同时执行不同平面同一地址的机制
para-zns设计
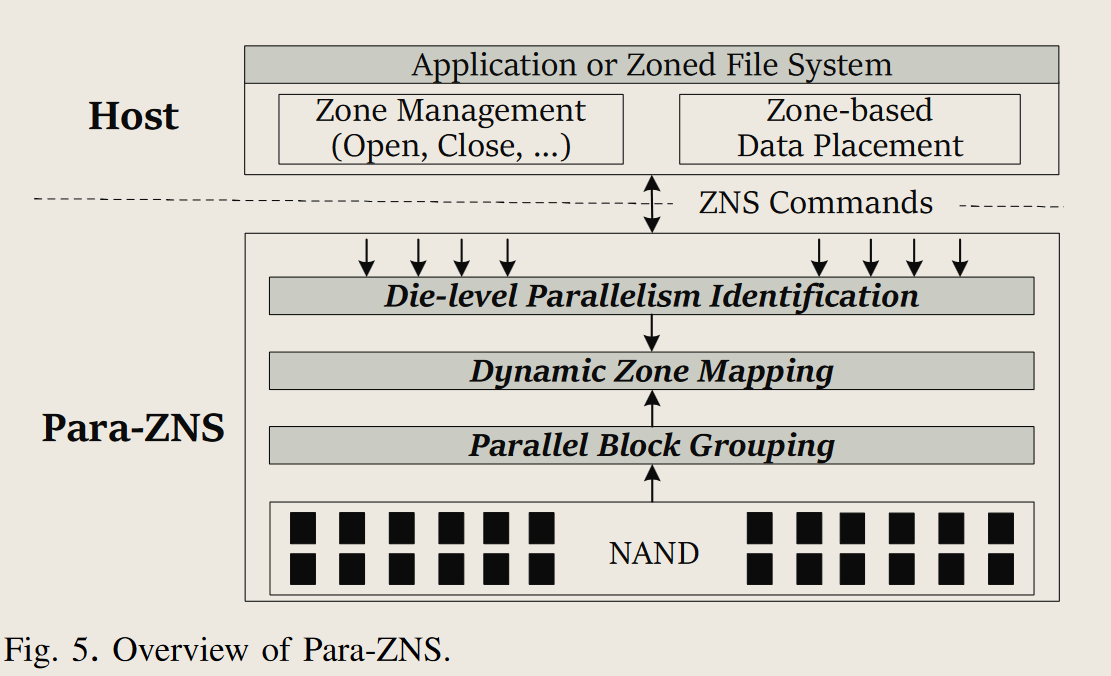
- Parallel block mapping 并行块分配
- 用于保证平面级别并行性
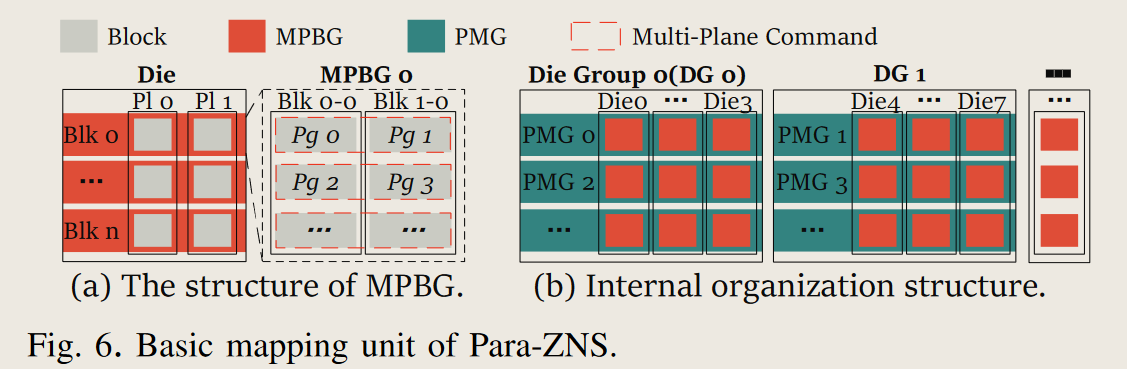
- MPBG: 将die内所有平面同一偏移的块组织为块组MPBG, 使得对MPBG的读写操作可以并行
- MPBG被作为最小粒度的分区映射单元, PMG是zone的基本映射粒度
- chip内的所有die被划分为多个die group(DG).
- DG内部相同偏移的MPBG被组织为parallel MPBG group(PMG)
- 该机制没利用到全部的chip并行性
- die-level parallelism identification die级并行性识别
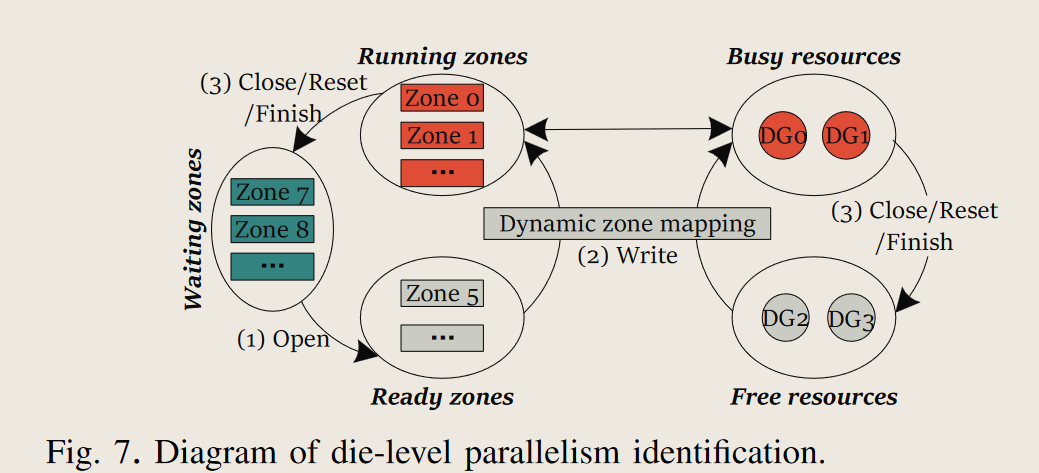
- 将zone分为waiting/ready/running三组
- 当ready状态zone等待DG的分配, 完成后转移到running状态, running状态的分区的DG被视为busy, 其他的DG为idle
- dynamic zone mapping 动态分区映射
- 将PMG映射到Ready状态的分区, 优先使用idel的DG以利用die级的并行性
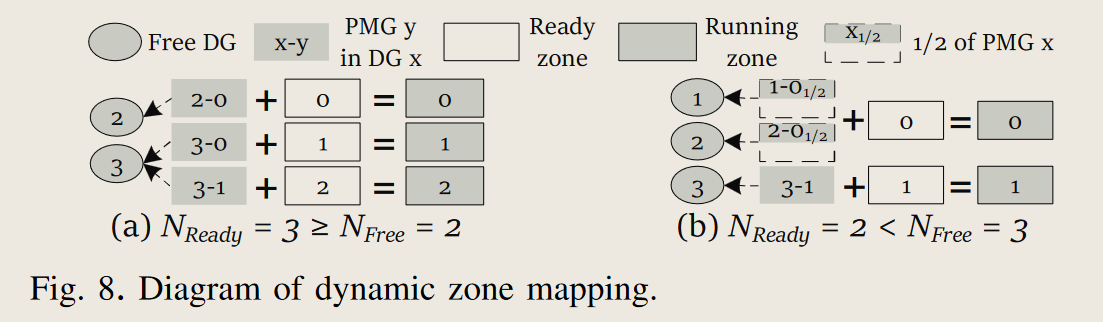
- 当ready分区多余空闲DG时, 优先分配空闲DG, 然后以轮询方式分配DG实现负载均衡
- 当ready分区少于空闲DG时, 将多个DG的部分PMG映射到同一个redy分区, 以提高die并行性
ZonesDB: Building Write-Optimized and Space-Adaptive Key-Value Store on Zoned Storage with Fragmented LSM Tree (ACM Transactions on Storage 2025)
摘要
- 动机: 碎片化日志结构合并树FLSM在键值存储上应用潜力大, 更小的写放大, 与LSM同样的顺序写特性
- 挑战: 主机发起的GC会增加总写入量, 抵消FLSM的写放大, 而FLSM有空间放大, 增加了开销
- 方法: ZonesDB基于FLSM的键值存储, 具备区域感知技术
引言
- 难点
- 主机发起的GC会恶化写放大, 抵消掉FLSM的收益, 并且FLSM有较高的空间放大, 导致整体收益高
- 基于追加的合并压缩是一把双刃剑, 缓解LSM的写放大, 但是消耗了更多的空间
- 设计
- 写优化 – 通过避免GC避免恶化写放大
- 空间适应 – 可用空间自适应抑制FLSM的写放大(区域感知)
- ZonesDB加入了zone-aware data management layer, 不仅按分区存储抽象组织KV存储的文件, 还整合了分区存储接口
- 提出了区域感知的附加合并压缩机制, 一次性压缩所有涉及分区中的SSTable
- 区域感知空间适应机制, 动态适用可用区域空间, 抑制FLSM的写放大
- 性能
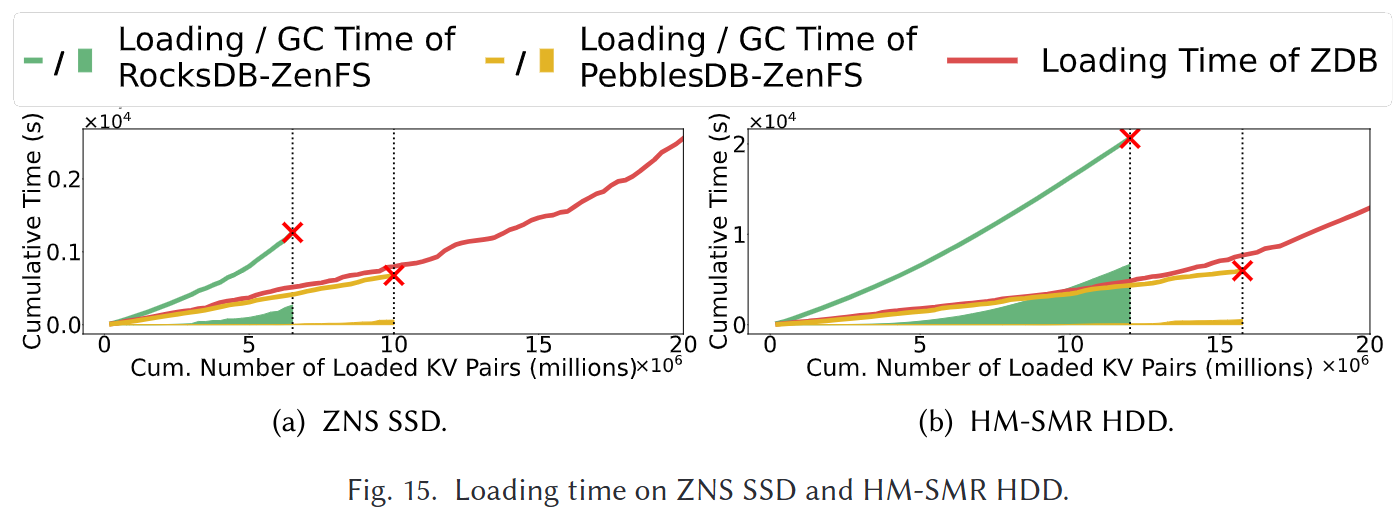
首先, ZonesDB至少可以将总写入放大率降低58.37%, 并且至少可以提高44.12%的写入性能.
此外, ZonesDB成功地将基于FLSM树的键值存储的空间放大率降低至多9.05%, 并以相似的磁盘空间容纳相同数量的数据写入到基于LSM树的键值存储.
- 难点
背景与动机
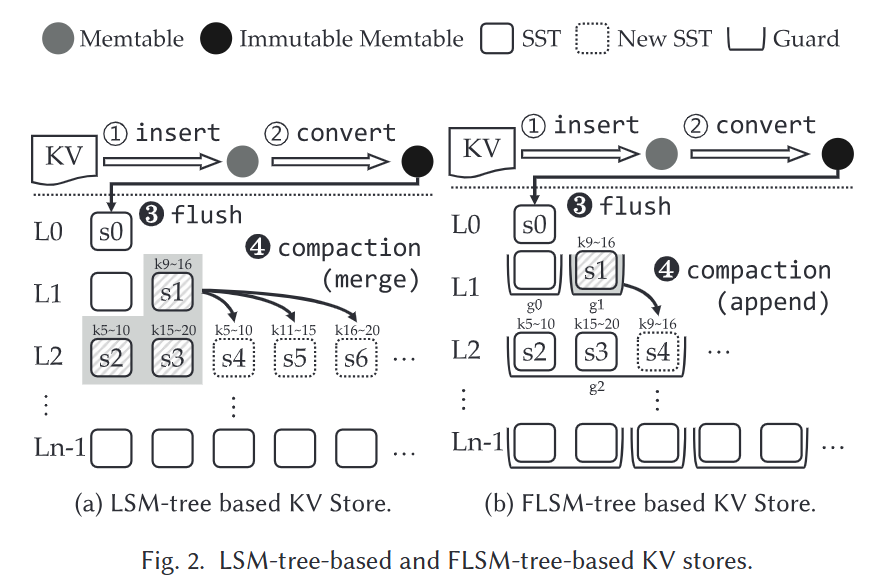
- LSM-Tree based KV-store: LevelDB, HyperLevelDB, RocksDB
- FLSM-Tree based KV-store: PebblesDB (SOSP ‘17)
- FLSM引入了守卫Guard, 除L0外每个级别被组织为多个非重叠的守卫, 每个首位内部可用包含多个互相重叠的SSTable
- 基于守卫设计, 后台压缩可用直接将新创建的SSTable追加到下一级别的适当守卫中, 被称为基于追加的压缩, 图2b中s1被直接写到g2中, 没有与s2和s3做合并
- 在分区存储上应用FLSM-Tree的挑战
- 主机发起的GC放大了总写入量, 抵消了FLSM低WA优势, 导致设备磨损和性能下降
FLSM和Zoned Storage间存在鸿沟, PebblesDB的GC写入量达到总写入量的70% - Append Compaction会导致空间放大高, 增加分区存储的开销
- 主机发起的GC放大了总写入量, 抵消了FLSM低WA优势, 导致设备磨损和性能下降
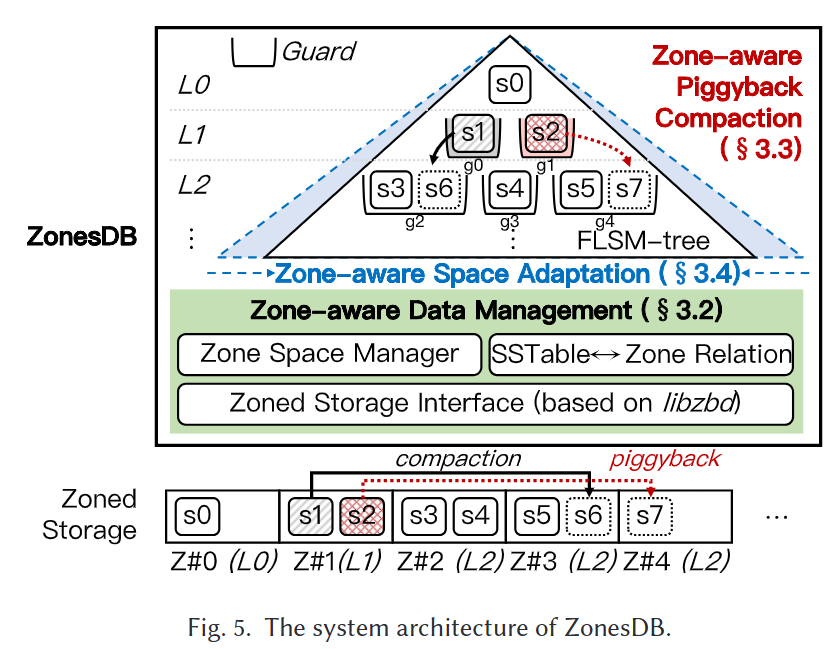
ZonesDB设计
整体架构
- zone-aware data management layer: 管理空间, 维护sstable和zone间的双向关系, 整合分区存储接口以适应ZNS和SMR
- zone-aware piggy-back compaction: 消除GC带来的写放大
- zone-aware space adaption: 缓解FLSM的空间放大
分区感知的数据管理
- 分区空间管理 zone space manager:
- 总体思想按照现有做法: 分区只容纳单一层级的SSTable, 以适应分区的回收与重置, 如COZA, SEALDB, GearDB
- 为每个Level保留一个打开的分区, 并跟踪其写指针wp, wp直接可通过libzbd的设备report拿到
- 在内存中维护一个数组指示区域状态, 空/打开/满, 还能跟踪可用磁带总数, 状态直接由分区起始LBA和wp的关系拿到
- SSTable $\leftrightarrow$ Zone关系
- SSTable $\rightarrow$ LBA, 维护SSTable到分区的映射
- Zone $\rightarrow$ SSTable, 维护分区中存放了哪些SSTable, 用于zone-aware piggyback compaction阶段
- ZonesDB沿用PebblesDB的崩溃一致性机制, MANIFEST记录有效SSTable的元数据变化, 通过MANIFEST元数据恢复崩溃前状态; ZonesDB会把S2L写入MANIFEST
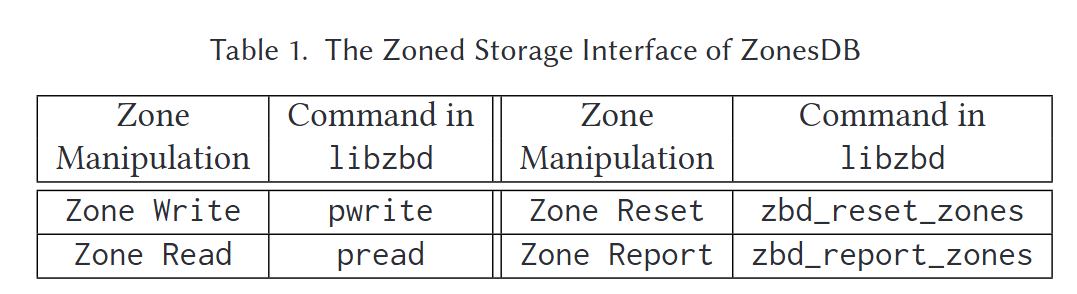
- 分区存储接口
- 通过整合libzbd形成ZonesDB的接口
- 分区空间管理 zone space manager:
分区感知的附加压缩 – 针对GC写放大
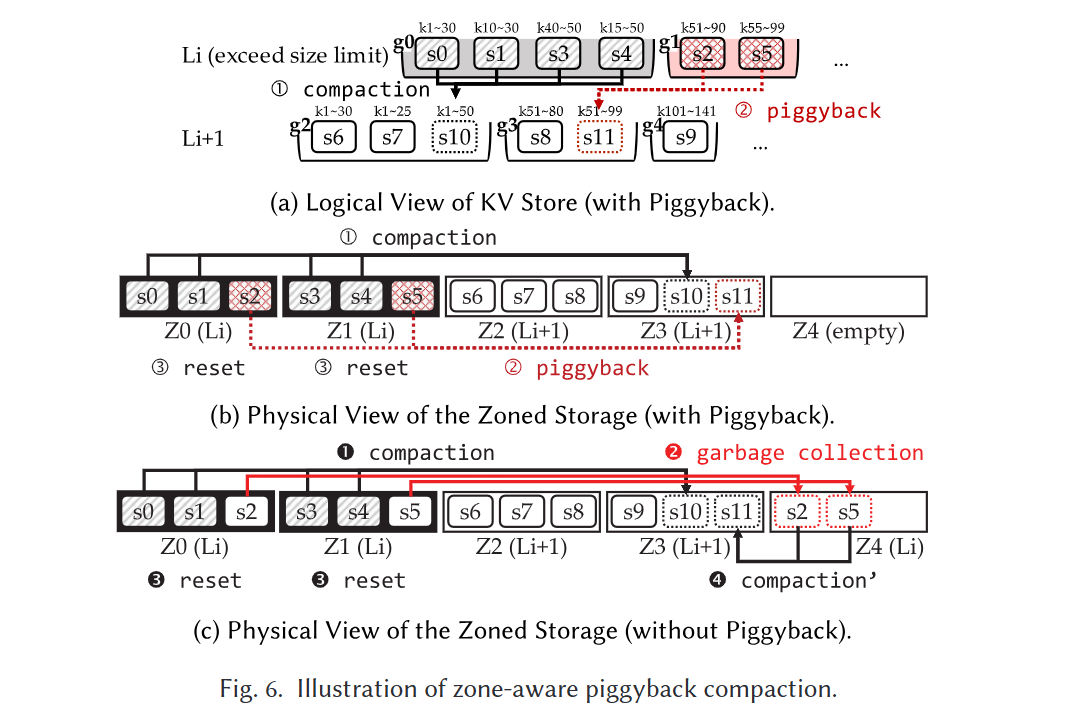
- 在选出驱逐守卫victim guard后, 不仅压缩其中的SSTable, 还顺带将涉及的Zone中所有SSTable压入下一层Guard中, 使得在重置时无需额外迁移
- 如图6a所示, g0被选择为驱逐守卫后, 完成合并压缩, 由于g1中s2与s5与g0中所示SSTable在同一分区中, 所以会执行附带压缩生成s11写入$L_{i + 1}$中的其他guard中, 这样z0和z1就可以0GC重置了
- 极端情况下驱逐guard可能与很多个Zone有关, 使得需要很多空分区来执行附带压缩; 为此, 会检查驱逐守卫中关联的分区数是否超过当前可用分区数, 如果是则只选部分做附带压缩. 附加压缩同样使用后台进程来执行
区域感知空间自适应 – 针对空间放大
- (1) 如何选择victim guard以最大化抑制空间放大; (2) 如何动态将空间放大适应到可用空间
- 抑制效率 suppersion efficiency: 直接扫所有Guard的SSTable计算过期总数不可行, 大量IO; 启发式规则, 通过guard内SSTable数量评判过期KV对数, 优先对SSTable多的guard做合并压缩
- 抑制适应 suppersion adaption: 随着可用zone的减少应减少guard内平均SSTable数目$\overline{sst}$, 而可用zone则用空zone与总zone的比值确定
$$\frac{1}{\overline{sst}}<1-\left(\frac{Z_{empty}}{Z_{total}}\right)^n $$
具体实现
- 基于PebblesDB改进
- 守卫管理: 继承PebblesDB的守卫选择模式, 键值对的后x位决定是否是否在同一层中形成guard, 以异步形式将guard插入FLSM
- 性能增强: 多线程读Guard内SSTable, 通过seek compaction在评分范围查询时做合并压缩
性能评估