NVMe规范与技术细节
NVMe技术细节
参考自编程随笔NVMe专题
1 NVMe技术概述
- AHCI: Serial ATA Advanced Host Controller Interface, 串行ATA高级主机主控接口
- AHCI, NVMe, SATA, PCIe关系, 设计之初NVMe主要服务于PCIe SSD
- NVMe的特点与优势
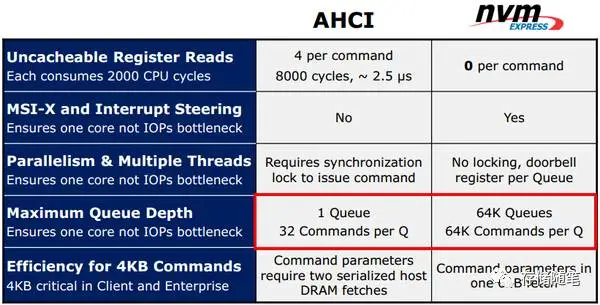
- 高速, IO延迟低(PCIe不需要和SATA一样连接到南桥中转, 直达Root Complex)
- 理论上IOPS与队列深度(Queue Depth)和IO延迟有关, 用数学表达式是 $IOPS=队列深度/IO延迟$, NVMe支持64K个深度为64K的队列, 所以IOPS高
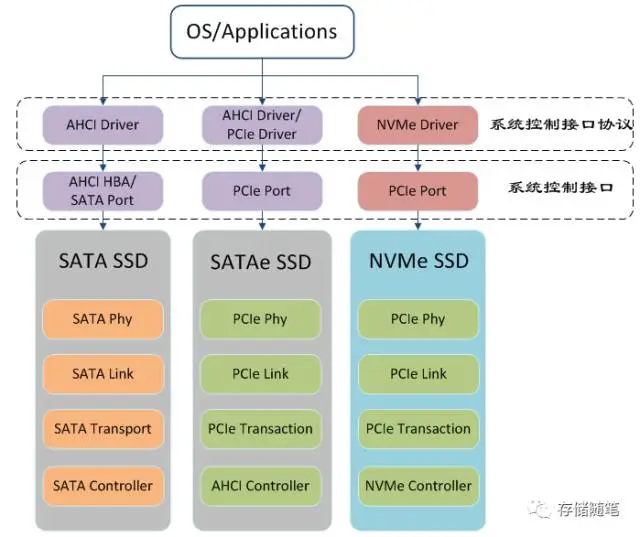
2 队列管理 Queue Manage
- NVMe命令种类

当Host要下发Admin command时,需要一个放置Admin command的队列, 这个队列就叫做Admin Submission Queue, 简称Admin SQ.
Device执行完成Admin command时,会生成一个对应的Completion回应, 此时也需要一个放置Completion的队列, 这个队列就叫做Admin Completion Queue, 简称Admin CQ.
同样, 执行IO Command时, 也会有对应的两个队列, 分别是IO SQ和IO CQ.
- Admin SQ/CQ放Admin管理命令, 管理SSD, 队列2~4K
- IO SQ/CQ放IO命令,完成数据传输, 队列2~16K
- 系统中只有一对Admin SQ/CQ, 可以有最多64K对 IO SQ/CQ, SQ命令条目大小为64K, CQ命令完成状态条目大小16K, IO SQ/CQ可以一对多也可以一对一
- Admin和IO的SQ/CQ均放在Host端Memory中, SQ由Host来更新,CQ则由NVMe Controller更新
- Doorbell Register/Pointer Register
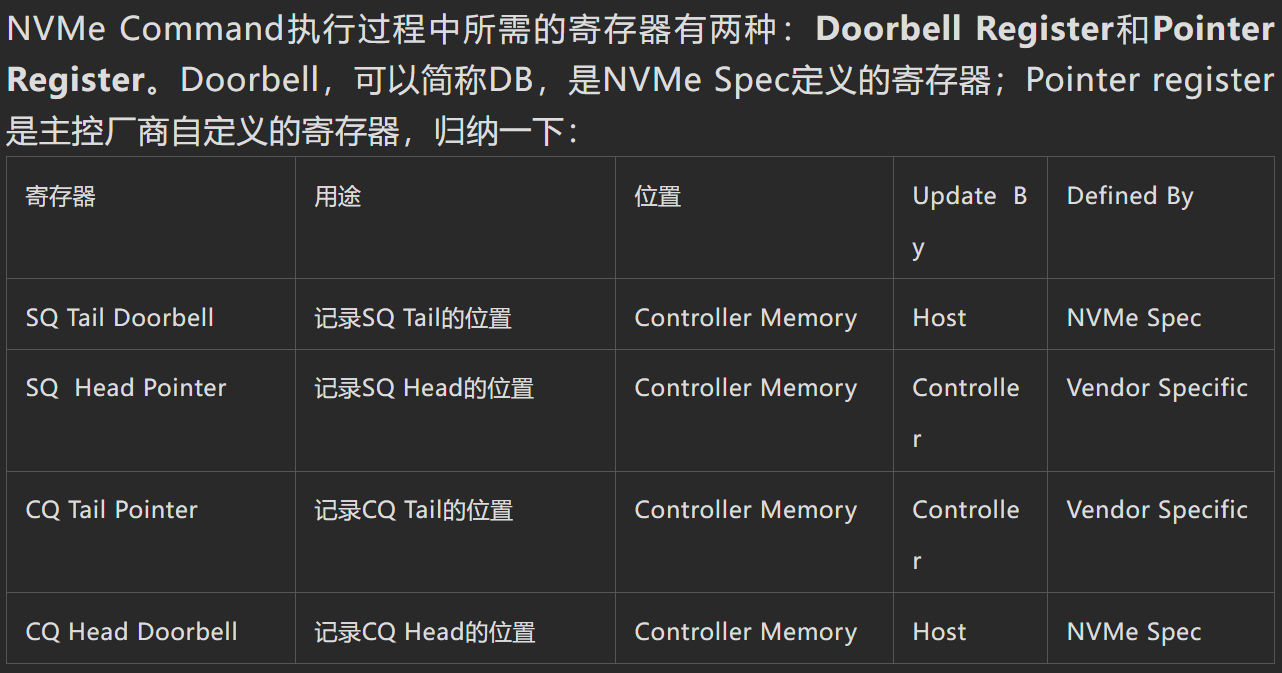
- 由于SQ/CQ均位于控制器内存, Controller把SQ Head和CQ Tail的信息写入了Completion报文, 让主机看到工作状态
3 命令仲裁机制 Arbitration
- NVMe Spec没有规定命令放入SQ的执行顺序, Controller可以一次取多个命令批量处理. 一个SQ中命令执行顺序不是固定的, 多个SQ间的顺序也不是固定的, 涉及命令仲裁机制
- 循环仲裁: 所有Admin SQ和IO SQ优先级一样, 按序从所有SQ中取出一定数目(通过Set Feature定义)命令
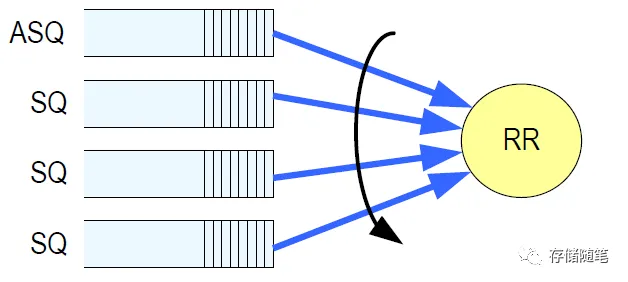
- 加权循环仲裁: 三个绝对优先级和三个加权优先级
Admin Class: 最高优先级, 必须最先执行, Admin SQ为该优先级Urgent Class: 该类IO SQ必须在Admin SQ之后执行WRR Class: 最低绝对优先级, 有High, Midium, Low三个加权优先级
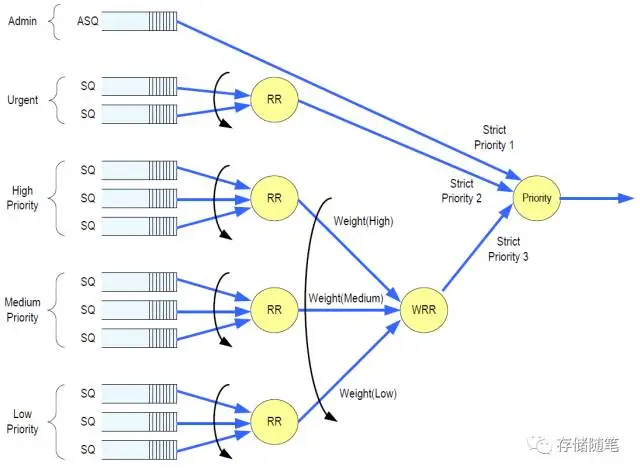
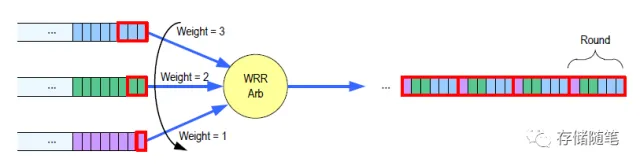
- 先3给weight=3的, 再2个weight=2的, 然后1个weight=1的
4 寻址模型PRP和SGL解析
当Host下发NVMe Write命令时, Host会先放数据放在Host内存中, 然后通知Controller过来取数据. Controller接到信息后, 会通过PCIe Memory Read TLP读取相应的数据, 接着Host返回的PCIe Completion报文中会携带数据给Controller, 最后再写入NAND中.
当Host下发NVMe Read命令时, Controller先从NAND中读出相应数据, 然后通过PCIe Memory Write TLP将数据写入Host内存中.
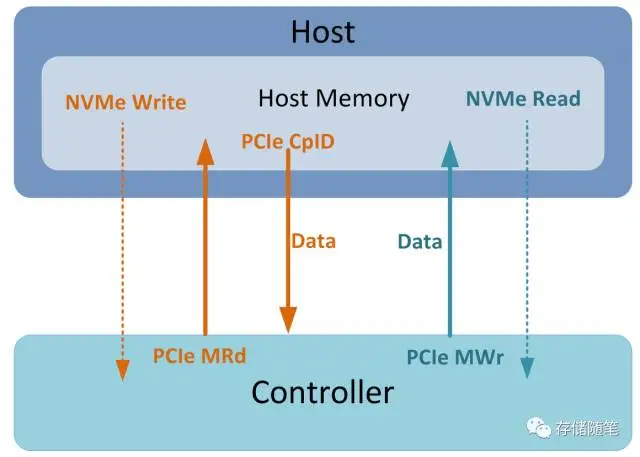
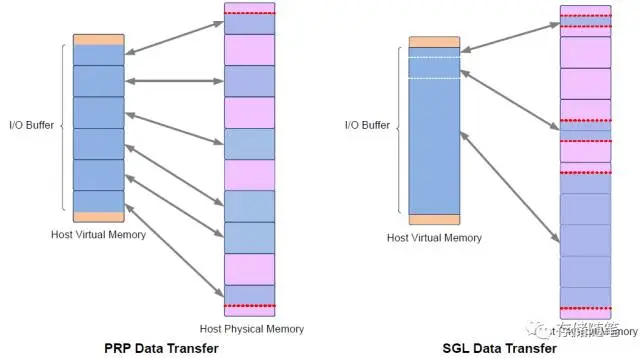
- NVMe Controller通过PRP和SGL这两种模型获取数据再host内存中的地址
- PRP(Physical Region Page), 记录host内存中物理页位置. PRP entry是一个64位的结构, 高[64:n]位是物理页的基地址, 低[n:0]位是页内偏移, n由物理页大小决定
- NVMe Command中定义了两个PRP Entry, 第二个Entry偏移为0, 若需要传输的数据超过了两个物理页(即2个PRP entry不够), 则第二个Entry指向PRP list, list中偏移为0
- SGL(Scatter Gather List), 再NVMe over PCIe中可用于IO命令, 不能用于Admin命令. SGL主要用于NVMe over Fabric
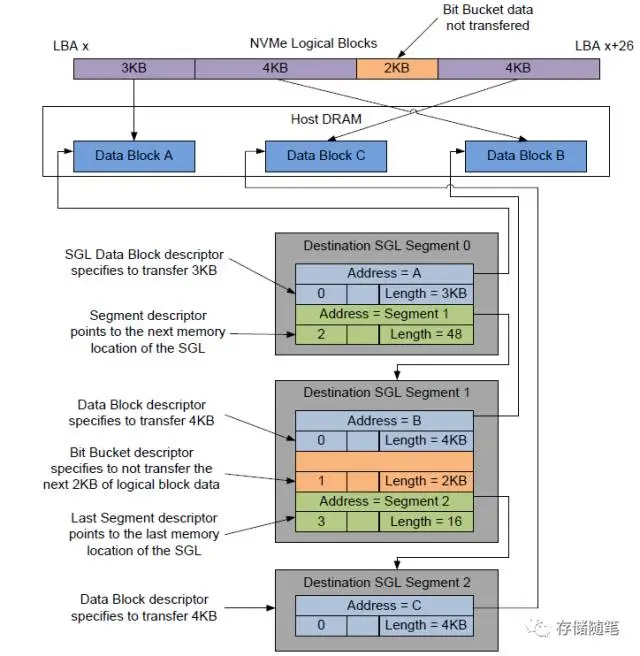
一个SGL包含多个SGL Segment. 一个SGL Segment包含多个SGL Discriptor. 其中, SGL Segment要求Qword对齐. 另外, 倒数第二个SGL Segment中的最后一个Discriptor有一个特殊的名字, 叫做SGL Last Segment Discriptor
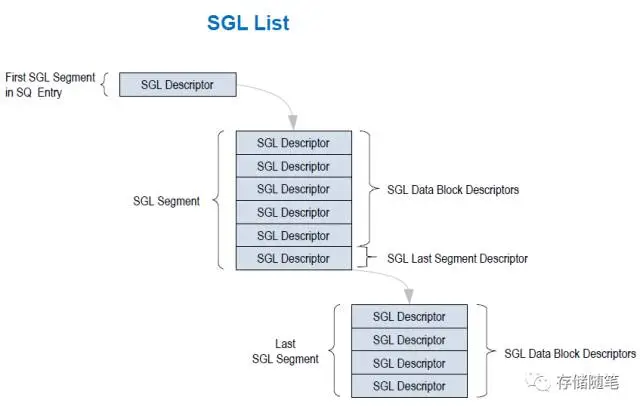
- SGL Bit Bucket Descriptor: 为Host服务, 告知Controller哪些数据是不必要写入Host内存
- Keyed SGL Data Block Descriptor: 代表了数据传输中带有密匙
PRP和SGL是描述Host内存物理空间的两种方式, 本质的不同是:PRP必须是物理页对齐的, 而SGL则可以表述任意的物理空间
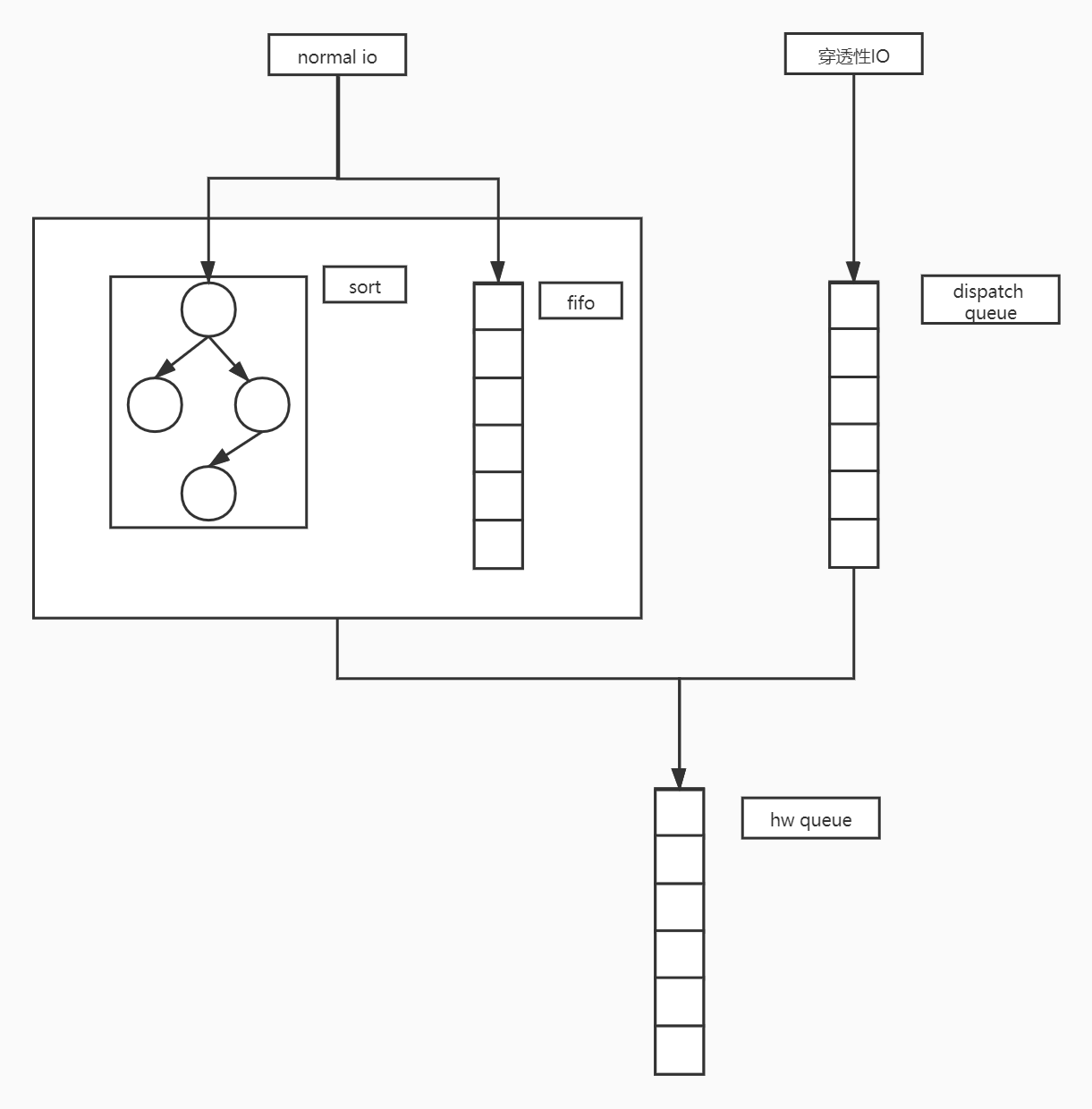
mq-deadline调度器原理
- 源码链接
- 适配block层多队列机制, 将IO分为read和write两类, 每类IO都有一个红黑树和fifo队列, 红黑树用于将IO按照LBA排序方便查找, fifo队列用于顺序保证, 并提供超时保障. 穿透性IO发送至dispatch队列
1 | |
- 一个块设备对应一个deadline_data, read可以抢占write的分发, 当达到饥饿starved限制时必须处理write.mq-deadline调度器会优先去批量式地分发IO而不去管IO的到期时间, 当批量分发到一定的个数再关心到期时间, 然后去分发即将到期的IO.mq-deadline调度器原理及源码分析
NVMe规范与技术细节
https://yee686.github.io/2024/12/05/NVMe技术细节/