常见的分布式存储系统(HDFS、Ceph、Swift、HBase)
常见的分布式存储系统(HDFS、Ceph、Swift、HBase)
在实习中接触到了很多分布式存储相关产品, 这一块知识不够系统, 跟着相关文档和论文梳理一下
分布式存储常见架构
中心控制节点架构
- HDFS是典型代表(我认为SMH也是类似架构, 有一个元数据管理中心)
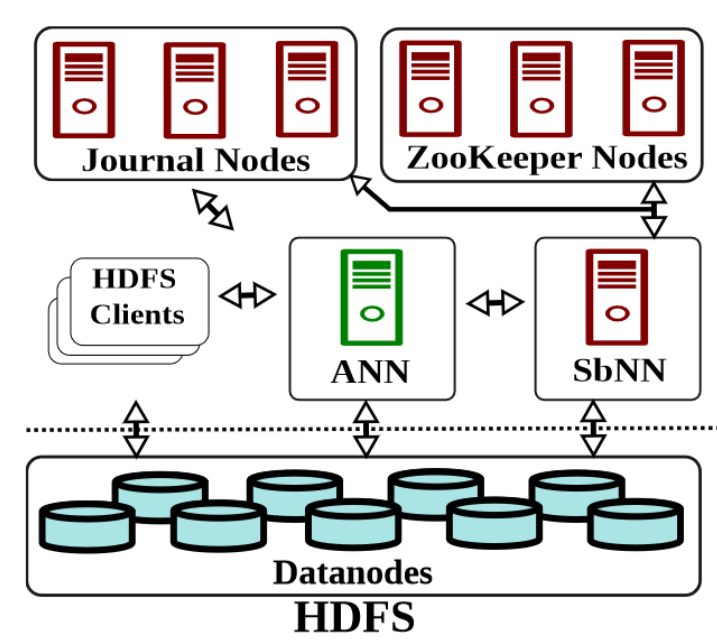
- NameNode用于存放管理的元数据, DataNode用于存放实际数据
- NN中记录了文件/数据在哪个DN上, NN一般是一主多备, DN由多个节点构成集群, 从访问上来说, NN单点较热, 而单个NN访问频率小很多, DN多副本形式保证高可用, DN可扩展性好
无中心架构 - 计算模式
- Ceph是典型代表, Ceph支持文件、对象、块三种存储类型
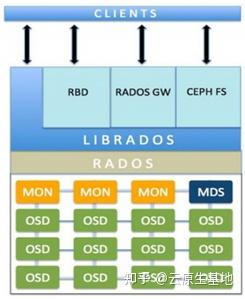
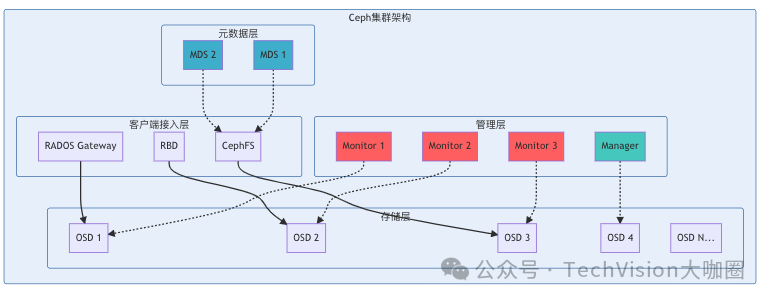
- 核心组件
- Monitor(MON): 维护存储系统的硬件逻辑关系(在线状态), 以集群方式保证服务可用性, MON
- Object Storage Device(OSD): 负责响应客户端请求返回具体数据的进程, 一个Ceph集群中有多个, 实现真正的数据读写, 通常一个磁盘对应一个OSD
- Ceph Metadata Server(MDS): CephFS依赖的元数据管理服务
- Placement Groups(PG): 逻辑概念, 一个PG包含多个OSD
- Reliable Autonomic Distributed Object Store(RADOS): Ceph集群的核心, 包含MON/OSD/MDS三种服务, Ceph中所有数据均以对象形式存储, 三种数据类型RADOS均以对象形式存储; RADOS保证最终一致性
- RADOS Block Device(RBD): 块设备, 提供可靠分布式、高性能磁盘
- CephFS: 使用Ceph存储集群存储用户数据并兼容POSIX接口的文件系统
- Librados: 接口库
- RADOS GW: RGW提供对象存储服务, 允许应用和Ceph对象存储简历连接(服务接入层), 提供兼容S3和swift的RESTful API
- 大致IO流程: 客户端->RGW->MON拉起存储资源布局信息->根据布局信息和写入数据名称计算期望位置->与对应CephFS通信读写数据
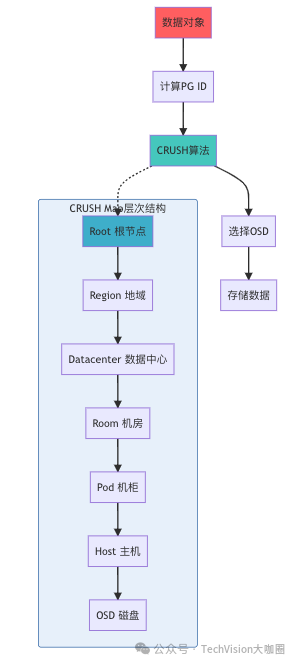
- CRUSH(Controlled Replication Under Scalable Hashing)算法
- 决定数据往哪儿放, 通过对象ID, 确定性计算该放到哪些OSD上
- (1) 对象 -> PG: 将对象映射到一个PG(逻辑分组), 静态哈希计算, 减少直接映射到OSD的计算量
- (2) 对象ID/PG ID/Cluster Map(集群拓扑图)/Placement Rule(分布策略,副本数/故障域约束等) -> OSD列表: 通过CRUSH算法将PG映射到OSD上

无中心架构 - 一致性哈希
- openstack Swift为典型代表, 只提供对象存储服务, 客户端请求需要经过代理层和存储层两部分, 提供最终一致性, Quorum仲裁协议
- 基本思想: 对于文件直接计算哈希值(MD5), 找到哈希环上的虚拟节点, 再映射到物理节点上
- 代理层 Swift-Proxy: 无状态服务模式, 多个节点组曾集群, 转发请求到数据节点
- 存储层 Swift-Storage-Nodes: 数据存储寻址服务(Account、Container、Object), 数据一致性保护服务(Replication、Updater、Auditor)
- swift对象存储组件
- 账户 Account: 类似租户的隔离的命名空间, Account与下级Container数据存储与SQLite中
- 容器 Container: 类似目录, 将对象数据逻辑分割, 由用户自定义
- 对象 Object: 客户端请求的物理文件, 包括数据和元数据, 以文件形式存储与节点文件系统上
- PUT/GET操作均对逻辑路径(Account/Container/Object)进行哈希计算, 得到对象的唯一标识
- 数据映射过程
- Swift将存储资源划分为固定数量的partition
- Ring维护partition到设备的映射关系, 包含Device Table(设备信息表)/Replica2Part2Dev Array(每个Partition的多个副本对于的设备ID)
- hash(Account/Container/Object) = XXX(Region + Zone + Node)
- 遵循故障域隔离防止副本, 有限选择未存放过副本的Zone、Node、Device, 根据设备weight跳匝副本分布
- Swift Ring: 一致性哈希环
对比
- HDFS: 适合大文件存储, 适合低写多读业务
- Ceph: CRUSH算法分布均匀, 并行度高, 一般用于对象存储和块存储, 扩容时会出现性能降级, 跨集群强一致性
- Swift: 最终一致性, 通过统一网关获取数据
参考资料
一致性
- 强一致性: CP(一致性 + 分区容忍性), 任何时刻所有节点数据都保持一直, 都能获取最新的数据, 包括2PC、Paxos、Raft
- 最终一致性: AP(可用性 + 分区容忍性), 允许数据更新后, 各副本展示不一致, 一段事件后最终一致, 包括
Apache Hadoop生态
- 核心
- HDFS 存储层, 分布式、多副本、高吞吐的文件系统
- YARN 资源管理层, 在hadoop 2.0中将资源管理、job调度/监控分离了出来形成的, 更加通用化, Spark、Flink也可在Hadoop上运行
- ResourceManager(RM): 管理系统资源
- NodeManager(NM): 位于每个工作节点上, 负责启动、监控容器并向RM上报
- ApplicationMaster(AM): 每个job都有一个AM, 用于申请资源, 与NM协作调度具体任务
- 数据处理与计算引擎
- MapReduce
- Apache Spark
- Apache Flink
- 数据集成与管理工具
- Apache Sqoop 实现hadoop仓库与外部RDB键数据传输迁移的组件
- Apache Flume 日志收集、聚合、传输
- Apache Kaffa 消息队列, 解耦、异步、削峰填谷
- Apache Hive 基于Hadoop的数据仓库工具, 将HQL查询转为MapReduce/spark集群上的job, 适用于批处理
- Apache HBase 分布式、可扩展的NoSQL数据库, 实现高校的实时读写
- 协调与治理工具
- Apache Zookeeper 分布式协调服务, 解决类似选主、配置管理、分布式锁的功能,保证各组件的一致性和可靠性
HDFS详解
组成架构
- NameNode 名称节点
- 存储HDFS元数据, 维护未见系统中所有的目录树
- 配置副本策略
- block映射信息维护, 持久化文件->block的映射, 但是不持久化Block->DataNode映射, 由DataNode在启动时后定期发送的块报告重建映射
- 持久化FsImage和EditLog
- FsImage 文件系统镜像: 是一个快照文件, 持久化某一时刻完整的文件系统命名空间和文件->block的映射
- EditLog 类似WAL记录所有对元数据的更改
- 处理客户端的读写请求
- DataNode 数据节点
- 存储实际数据块, 执行数据读写
- 启动时讲自己注册到NameNode, 并定期上报持有的块列表
- Client 客户端
- 文件上传HDFS时, 切分文件并上传
- 与NameNode交互获取文件位置信息
- 与DataNode交互读写数据
- 支持对HDFS的管理和增删改查操作
- SecondaryNameNode 辅助名称节点
- 定期从NameNode下载当前FsImage(可能是旧的)和EditLog, 合并生存新的包含最新状态的FsImage, 讲新的NameNode传递给NameNode
- NameNode会用新的FsImage替换旧的FsImage, 清空EditLog
- Namespace 命名空间
- 文件系统的命名空间的层级结构类似文件系统
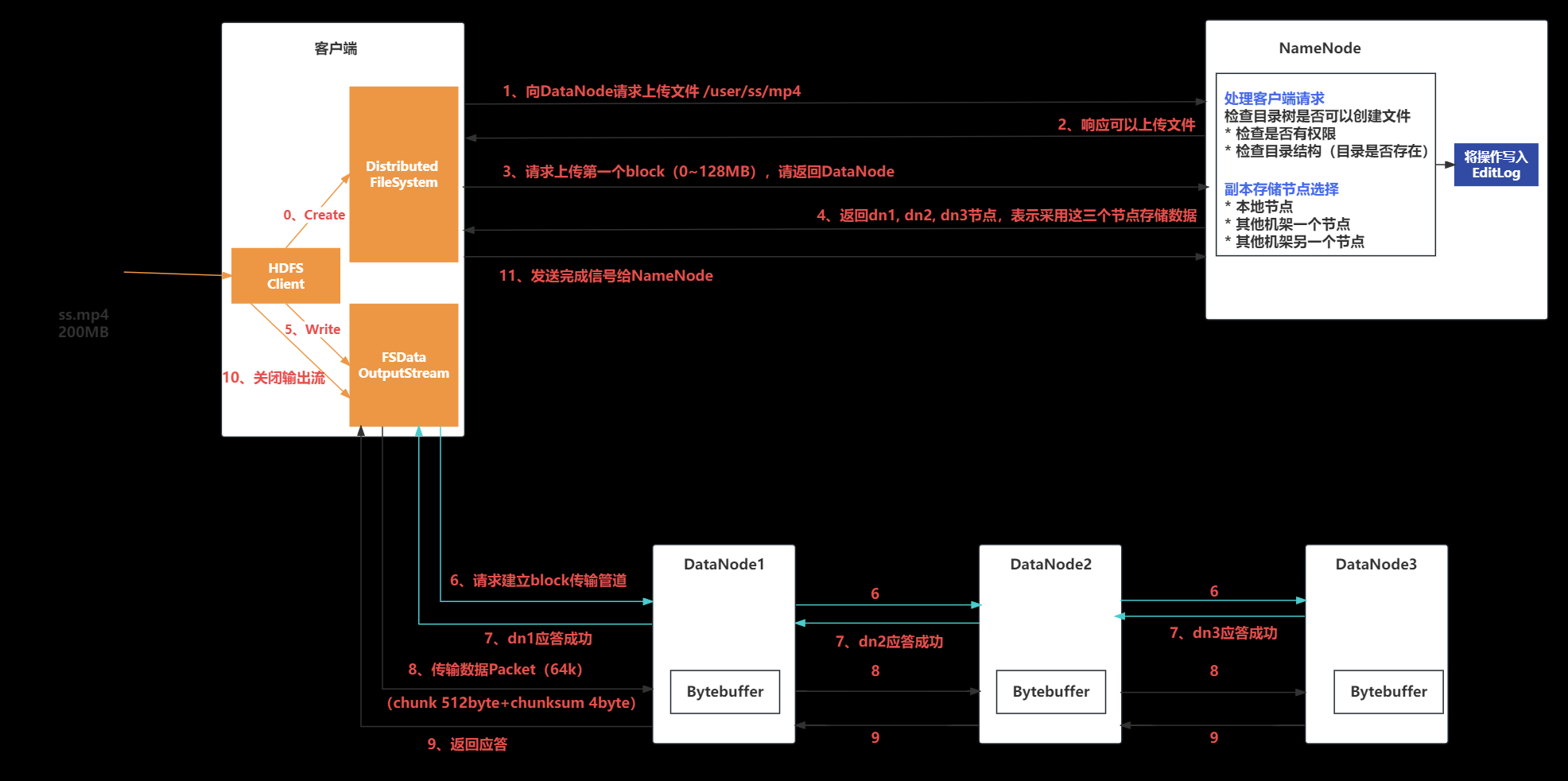
读写流程
- 写流程
- client发起文件创建请求
- NameNode检查元数据, 创建对应文件的元数据记录
- Client将数据ieru本地缓存, 会被切分成64K的package, 放入Data Queue中
- Client再次连信息NameNode, 获取DataNode列表, Client与目标DN构建管道
- Client将数据写入DN1, DN1写入磁盘, 并转发给DN2, DN2写完再转发给DN3…
- 写完后ACK会传给Client, 过程中有DN写入失败, NN会重写分配DN
- 当所有DN副本写入完成后, Client会再次通知NN, 提交块的元数据信息
- 读流程
- Client发送文件读请求
- NN饭hi改文件元数据, 包括文件包含哪些的数据块、各数据块副本的DN地址列表, 距离近的考前
- Client顺序依次读数据块, 首先会优先读拓扑距离最近的DN, 当某个DN读出错误, 则读下一个副本
- 当所有数据块读取完毕后, 关闭连接
HBase架构分析
- 基本概念: HBase是一种NoSQL数据库, 是分布式的、高可伸缩的大数据存储, 基于HDFS打造(类似RocksDB + ZenFS的结构, 只不过是分布式的, HDFS提供文件的管理/管理能力)
- 特性: 基于列族的kv存储
- 列式存储: RDB中的概念, 适合OLAP场景, 查询/聚合性能好, 压缩率高, 向量化执行(适合CPU的SIMD指令, 实现批处理提高查询速度), 代表有ClickHouse、BigQuery、Doris
- 列族: KV存储中常见, 源自bigtable, 一种数据分组/隔离的机制(独立物理结构如LSM-tree), HBase中列族包含多个列, 建表时列族是定好的, 列族中的列可以自由增删, HBase会把桶列族数据尽量放在同一个sever上
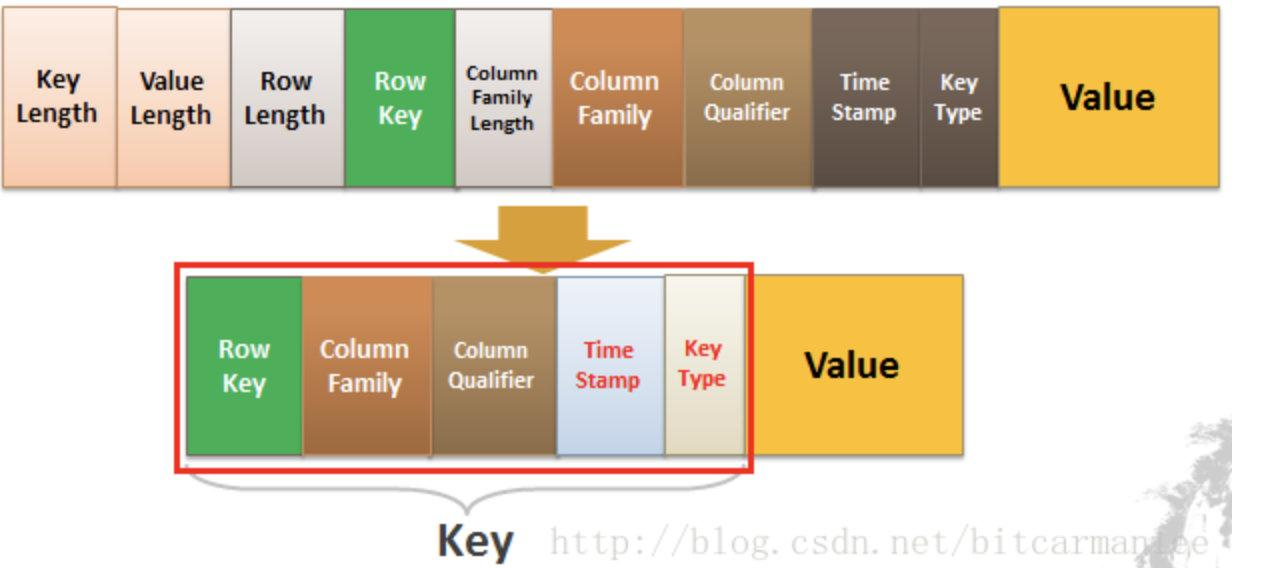
- HBase基于列族实现, 表中一行数据对应一个RowKey, 一个RowKey会对应到一个/多个列族(column family), 一个列族由一组相关的列(Column Qualifier标识列)+值(value)组成
- HBase的列族这里不同于RocksDB(一个列族中key对应一个value, 存多列的话有上层提供队Value的编码和解析/或者直接拼接成不同键key+column qualifier), HBase的
- 额外的Timestamp字段、Type字段实现, 辅助异地更新机制读数据
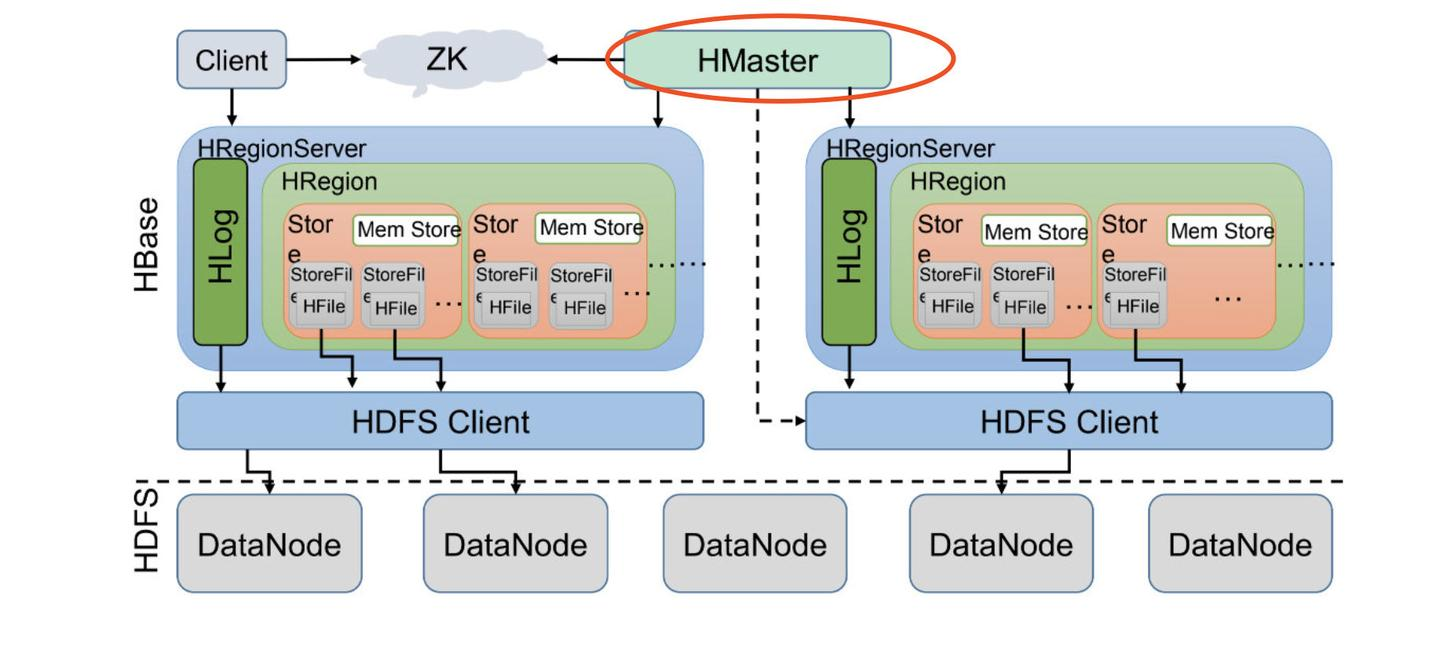
- HBase架构
- Client客户端 提供HBase访问接口, 维护对应Cache
- Zookeeper 存储HBase元数据, 读写均需要从Zookeeper中拿元数据
- HRegionServer 处理客户端请求, 与HDFS交互
- 内部为多个Hregion、一个预写日志HLOG, 一个表的数据根据Rowkey横向切片存储到不同HRegion上
- 单个HRegion内部有多个Store, 一个列族的数据存在一个Store上, 一个HRegion存储表的一部分数据
- Store内存汇总为Mem Store(写缓存类四memtable), 写满后flush形成StoreFile, 底层以HFile的格式持久化KV数据
- Hmaster用于处理HRegion的分配和转移, 对于数据量太大的HRegion, 会拆分后重写分配HRegionServer
- 大致读写流程
- client->zookeeper 获取元数据
- zookeeper->client 返回元数据
- client->HRegionServer 请求工作节点, 依次定位Region/Store
- HRegionServer->HDFS 请求HDFS
-
- 参考文献
常见的分布式存储系统(HDFS、Ceph、Swift、HBase)
https://yee686.github.io/2025/10/10/分布式存储/