RocksDB事务机制
RocksDB事务机制
官方文档
RocksDB使用TransactionDB/OptimisticTransactionDB支持事务功能, 提供了BEGIN/COMMIT/ROLLBACK API
TransactionDB: 基于悲观的并发机制, 所有写入的key都会被内部锁定以执行冲突检测, 如果无法锁定则返回错误, 只要DB可以写入则保证写入成功, 有一下三种写入策略WriteCommittedWritePreparedWriteUnprepared
OptimisticTransactionDB: 基于乐观的并发机制, 写入时不获取任何锁, 在事务提交时检测释放存在冲突, 如果存在冲突则返回错误并不执行任何写入高并发/频繁更新相同key适合使用
TransactionDB, 以少量的锁开销、写入操作的冲突检测开销来保证数据的成功写入; 少量的事务性写入适合使用OptimisticTransactionDB防止读写冲突
GetForUpdate(): 读取键时, 读取的值需要成为事务提交的前提, 其他事务修改了读取键的值时提交时会失败; 读改写RMW操作时, 读、写均独占key, 支持读写冲突检测- 快照机制snapshot: 默认情况下, 事务冲突检查会看自事务首次写入以来是否其他事务修改了键(即事务会对每一个修改的key加锁); 如果想要在事务开始以来外部没有写过某个键, 则需要通过
SetSnapshot创建快照, 然后在setsnapshot之后的所有操作, 当前事务独占
1
2
3
4
5
6
7
8
9txn = txn_db->BeginTransaction(write_options);
txn->SetSnapshot();
// 在事务外写入 key1
db->Put(write_options, “key1”, “value0”);
// 在事务中写入 key1
s = txn->Put(“key1”, “value1”);
s = txn->Commit();
// 事务将不会提交,因为在调用 SetSnapshot() 之后,key1 在事务外被写入
// (即使此写入发生在此事务写入该键之前)。
RocksDB事务隔离性
- 读提交的实现: 基于WriteBatch实现, 不同事物会分配对应的WriteBatch, 由WriteBatch处理具体写入操作, 读数据优先读当前WriteBatch
- 可重复读机制: 基于快照隔离机制实现, RocksDB会对每一个kv对添加版本号(Sequence Number), 全局递增, snapshot会和一个lsn绑定, 读数据时对于大于snapshot的lsn的key是不可见的
Write Batch With Index(WBWI)
- WriteBatch结构如下
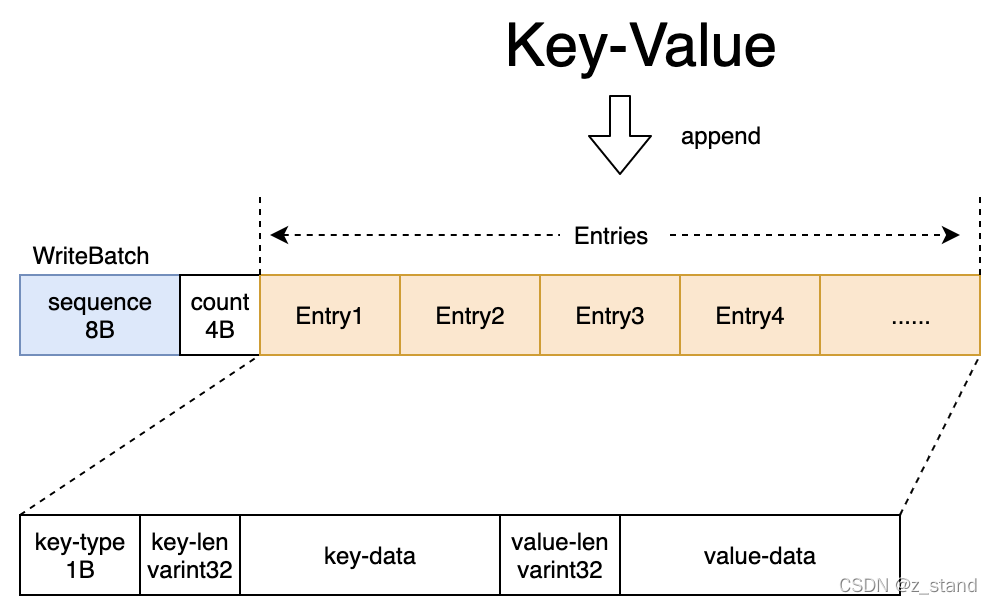
- WBWI结构如下: WB + skiplist, 支持读还未写入到Memtable的新数据, 事务的put操作, 会先在WB的string-buffer中加入entry, 再将该请求的offset、cf_id、key_offset、key_size插入跳表中
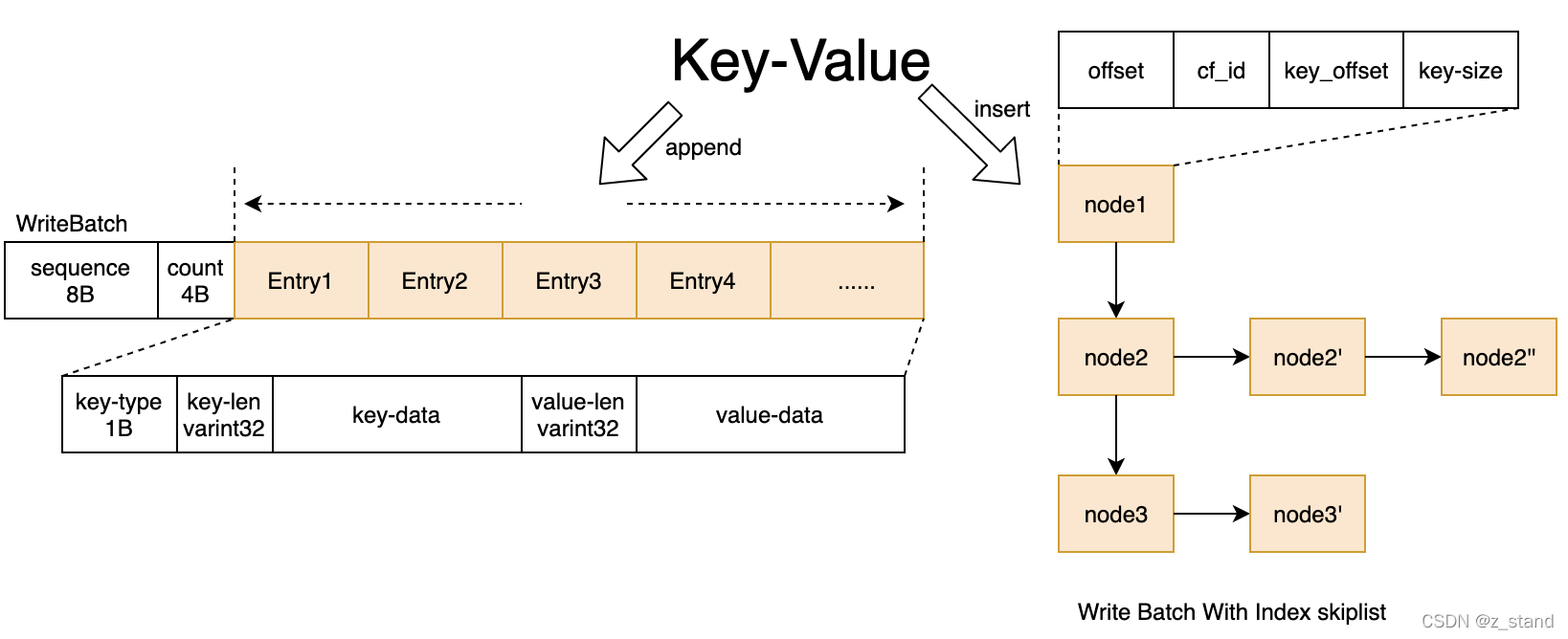
- 如果调用txn->SetSavePoint, 当前WBWI保存到栈(
std::stack<SavePoint, autovector<SavePoint>> stack), RollbackToSavePoint会进行弹栈
RocksDB事务机制
https://yee686.github.io/2025/09/25/RocksDB事务机制/